faast.js is a new framework that makes writing serverless functions super easy. Read more about it in this introductory blog post:
Faast.js started as a side project to solve the problem of large scale software testing. Serverless functions seemed like a good fit because they could scale up to perform work in parallel, then scale down to eliminate costs when not being used. Even better, all infrastructure would be managed by the cloud provider. It seemed like a dream come true: a giant computer that could be as big as needed for the job at hand, yet could be rented in 100ms increments.
But trying to build this on AWS Lambda was challenging:
* Complex setup. Lambda throws you into the deep end with IAM roles, permissions, command line tools, web consoles, and special calling conventions. Lambda and other FaaS are oriented towards an event-based processing model, and not optimized for batch processing.
* Primitive package dependency support. Everything has to be packaged up manually in a zip file. Every change to the code or tests requires a manual re-deploy.
* Native packages. Common testing tools like puppeteer are supported only if they are compiled specially for Lambda.
* Persistent infrastructure. Logs, queues, and functions are left behind in the cloud after a job is complete. These incur costs and count towards service limits, so they need to be managed or removed, creating an unnecessary ops burden.
* Developer productivity. Debugging, high quality editor support, and other basic productivity tools are awkward or missing from serverless function development tooling.
Faast.js was born to solve these and many other practical problems, to make serverless batch processing as simple as possible.
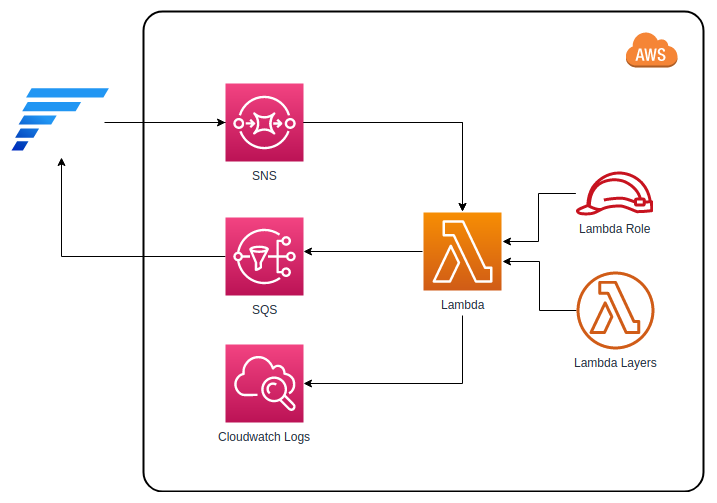
And here’s the quick visualization of the architecture for you.