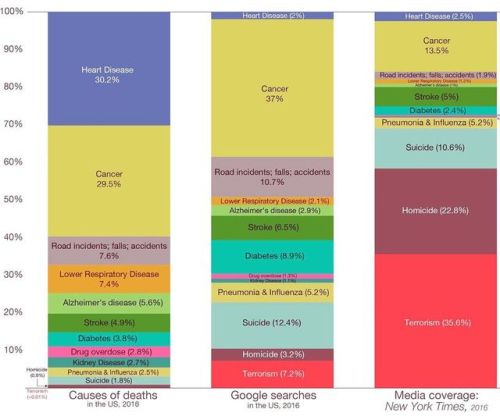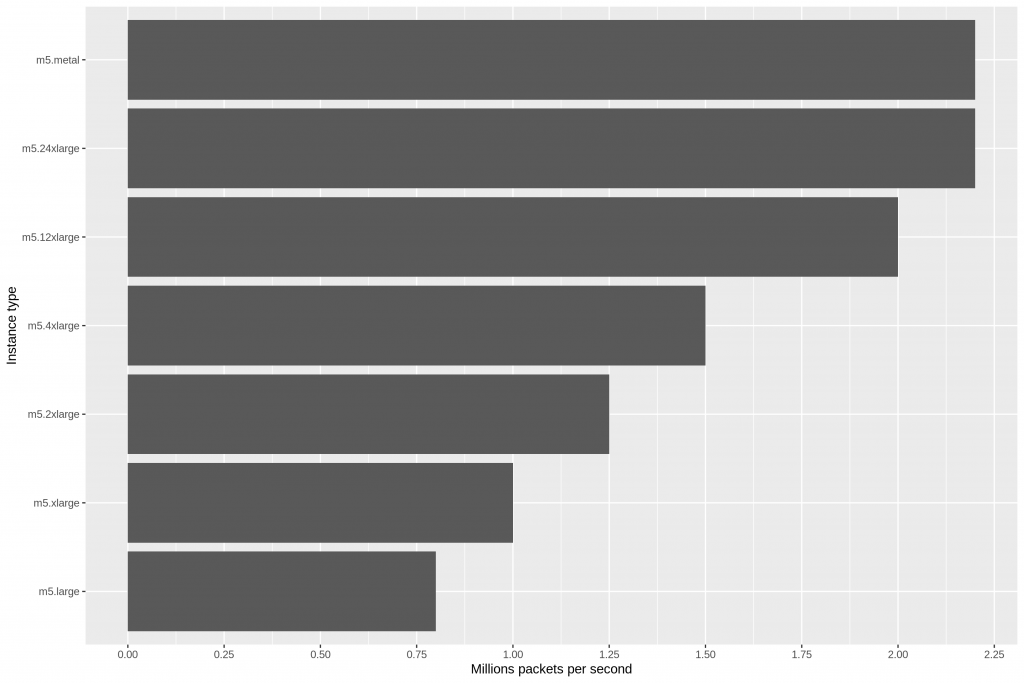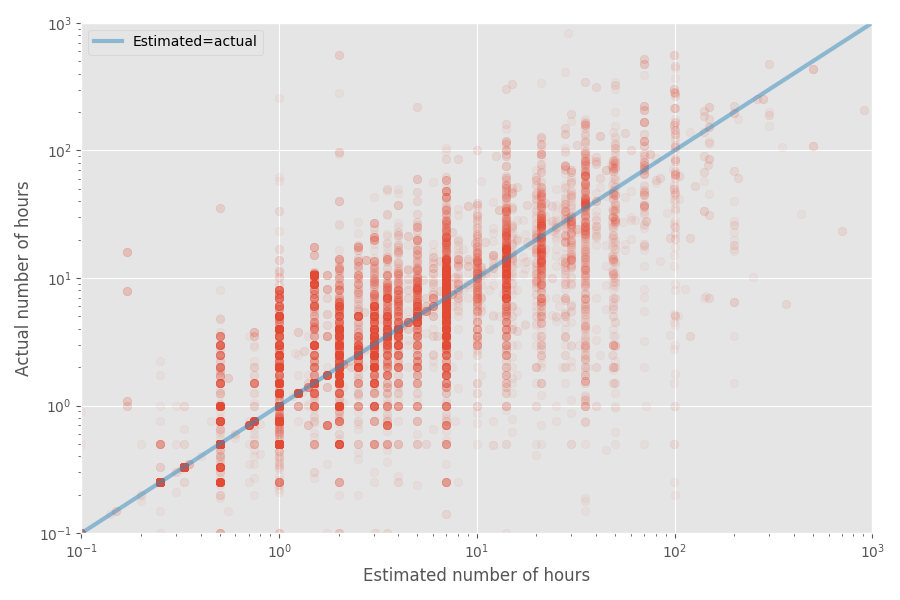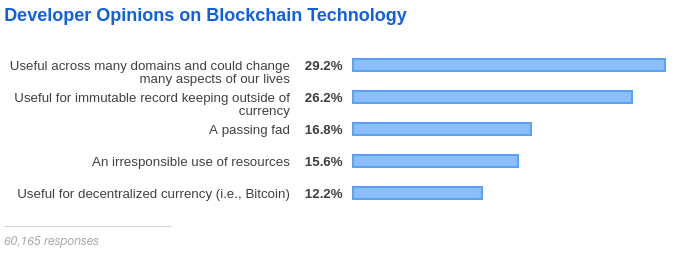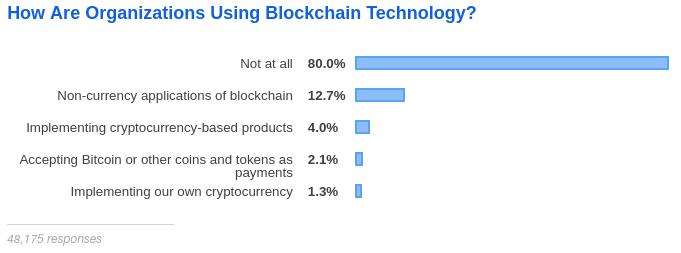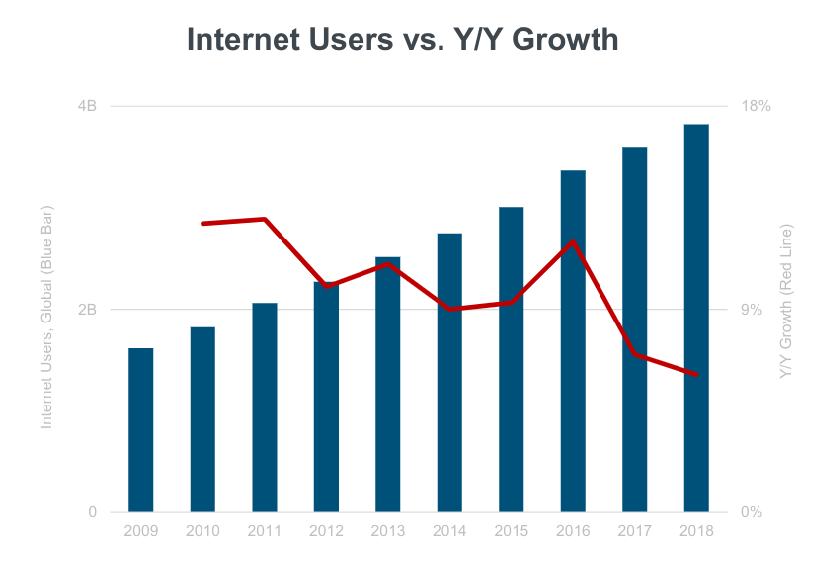
Internet Trends 2019 report is the most comprehensive, detailed, and research document that I have ever seen on what’s going on with the Internet, web, mobile, social media, marketing, and security.
This year’s report spans 333 pages and is full charts, graphs, statistics, insights, and references. And if you are feeling nostalgic, there is an archive of the annual reports going all the way back to 1995.
It’s difficult to pick a single fact from such a huge document, but if I had to, I’d go with this:
51% of the global population, or 3.8 billion people, were Internet users last year.
Wow. That’s quite a crowd.
Via Slashdot.