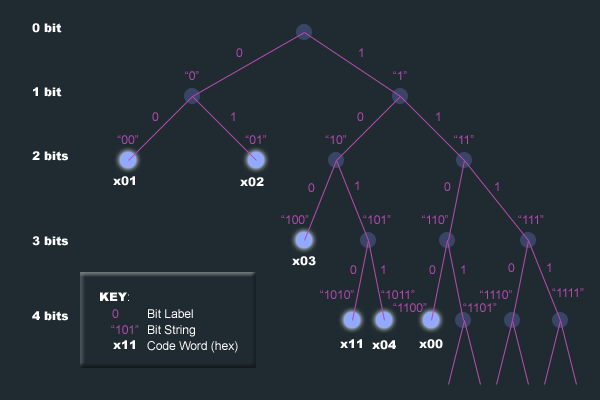
I came across this rather useful and practical tutorial on Huffman Coding in JPEG images. It looks at a very small and basic black-and-white image, and how the size of the data and overhead changes between different image formats, and then in more detail, how the Huffman Coding helps make that happen.
Unless you are dealing with compression, image formats, and binary trees on a daily basis, this tutorial is a good memory refresher of those college days.