Year: 2013
Ekisto – visualizing online habitats
Slashdot is linking to Ekisto – a project to visualize online communities like if they were cities. So far there are only GitHub, StackOverflow and Friendfeed (really? Friendfeed?). I’ve seen plenty of data visualization, especially for GitHub, but I have to say that this is one of the most interesting ones ever.
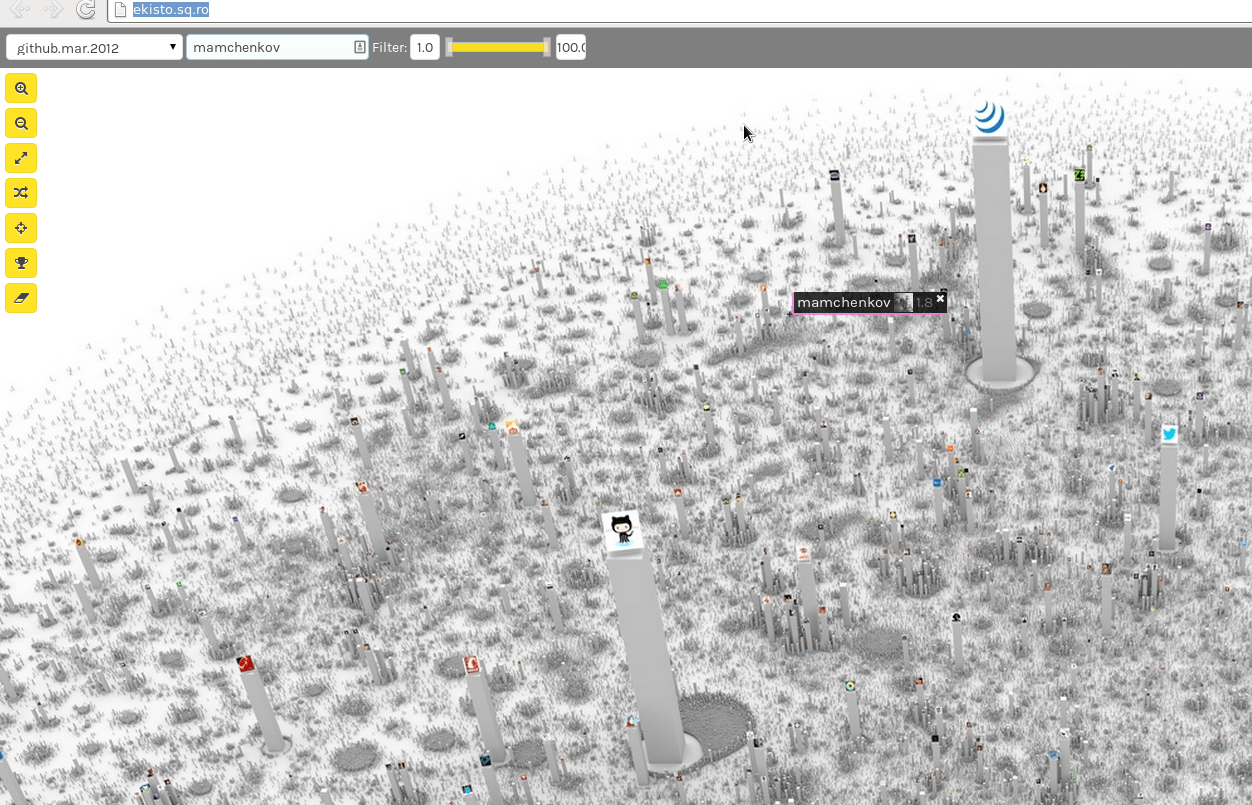
Here is a quote from the About page that explains how it works:
Ekisto comes from ekistics, the science of human settlements.
Ekisto is an interactive visualization of three online communities: StackOverflow, Github and Friendfeed. Ekisto tries to imagine and map our online habitats using graph algorithms and the city as a metaphor.
A graph layout algorithm arranges users in 2D space based on their similarity. Cosine similarity is computed based on the users’ network (Friendfeed), collaborate, watch, fork and follow relationships (Github), or based on the tags of posts contributed by users (StackOverflow). The height of each user represents the normalized value of the user’s Pagerank (Github, Friendfeed) or their reputation points (StackOverflow).
BayesDB – a Bayesian database table for querying the probable implications of data
BayesDB – a Bayesian database table for querying the probable implications of data
BayesDB, a Bayesian database, lets users query the probable implications of their data as easily as a SQL database lets them query the data itself. Using the built-in Bayesian Query Language (BQL), users with no statistics training can solve basic data science problems, such as detecting predictive relationships between variables, inferring missing values, simulating probable observations, and identifying statistically similar database entries.
BayesDB is suitable for analyzing complex, heterogeneous data tables with up to tens of thousands of rows and hundreds of variables. No preprocessing or parameter adjustment is required, though experts can override BayesDB’s default assumptions when appropriate.
BayesDB’s inferences are based in part on CrossCat, a new, nonparametric Bayesian machine learning method, that automatically estimates the full joint distribution behind arbitrary data tables.
browser-sync – Keep multiple browsers & devices in sync when building websites
Download your Gmail and Google Calendar data … soon or now
I am a well known Google fan. But even those who call it an Evil Corporation and a Global Spy, can’t argue with the awesomeness of these news:
Starting today we’re rolling out the ability to export a copy of your Gmail and Google Calendar data, making it easy to back up your data or move to another service.
You can download all of your mail and calendars or choose a subset of labels and calendars. You can also download a single archive file for multiple products with a copy of your Gmail, Calendar, Google+, YouTube, Drive, and other Google data.
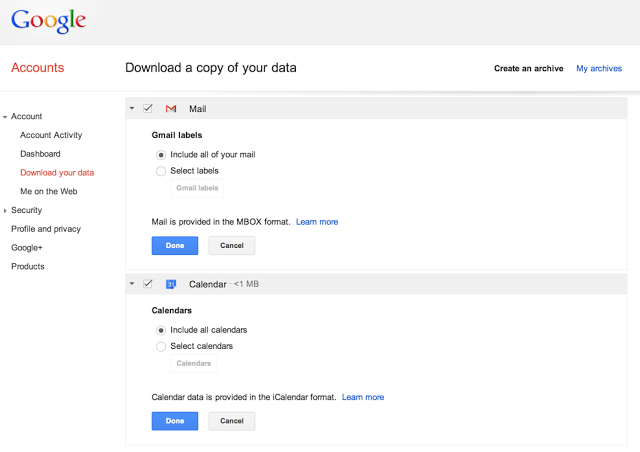
Most of the 20 GB of data I store on Google Drive is actually my email archive. I’ve imported email into my Gmail from as early as 1998 – much, much earlier than Gmail was even born. Having a way to export them all out in one go, without using clunky POP or IMAP is much appreciated.