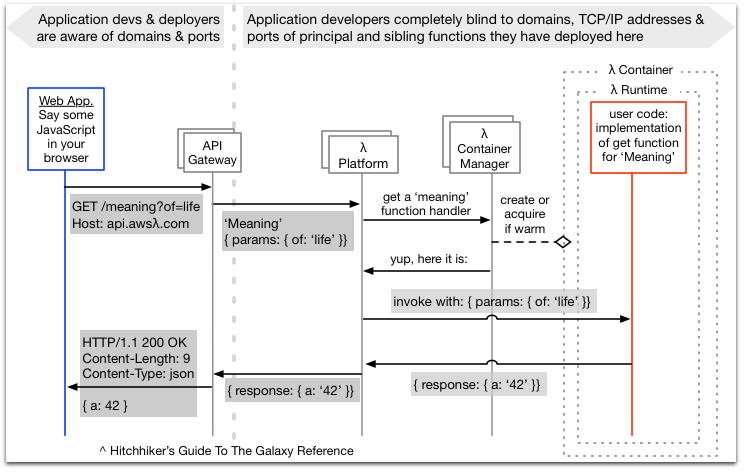
Paul Hammant has a quick and simple blog post illustrating the request-response sequence in the web application on a serverless infrastructure. I find it quite useful as a reference, when explaining serverless to people who are considering it for the first time.
This stuff and the abandonment of names:ports in the config is a key advance for our industry. It is like a limiting Unix problem has been overcome. While it is still is impossible for two processes on one server to listen on the same port (say port 443), it is now not important as we have a mechanism for efficiently stitching together components (functions) of an application together via the simplest thing – a name. A name that is totally open for my naming creativity (ports were restricted if they were numbered below 1024 and also tied to specific purposes) . We’re also relieved of the problem of having to think of processes now, and whether they’ve crashed and won’t be receiving requests any more. Here’s a really great, but rambling, rant on a bunch of related topics by Smash Company that you should read too as it touches on some of the same things but goes much broader.


