CrunchBase links to the StartupBlink’s “Ranking The Startup Ecosystems of 1,000 Cities and 100 Countries“.
The top 3 countries are USA, UK, and Canada. Cyprus takes 68th places out of a 100, climbing 6 places from the 74th place it was at in 2017.
The top 3 cities are San Francisco, New York, and London. Three Cyprus cities made it into the ranking:
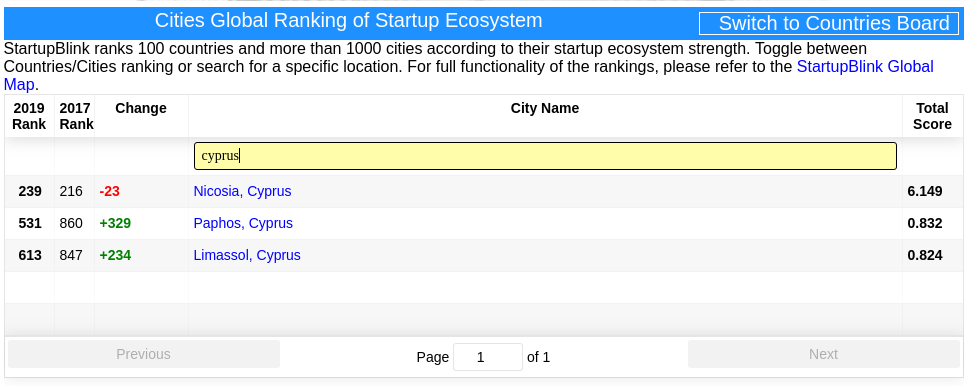
- Nicosia takes place 239, dropping 23 places from 216 in 2017.
- Paphos takes place 531, climbing 329 places from 860 in 2017.
- Limassol takes place 613, climbing 234 places from 847 in 2017.
I can find ways to justify Nicosia being so much higher than Paphos and Limassol. But Limassol being below Paphos looks strange to me.