In the comments, there are a few additional suggestions and links to other similar guides.
The only way this could have been better, if they included a ready-made template with all the described sections, so that one could just fill it in and be done with it.
I came across this nice article outlining some of the tips for implementing the software release process.
Software Development process is not complete and mature without a well-defined release process for the software applications. Every software application needs to be delivered or deployed at some point in time and for agile projects, this is happening more often. Therefore, there is a need to maintain software quality across the application releases to avoid deploying untested or malicious code to production environments.
Defining a release process for software applications helps in ensuring that software releases maintain a constant release quality. In addition, software changes and new features are traceable or can be correlated to specific releases easily. As a result, changelogs and release notes are easier for a generation.
I do agree with most of what is being suggested. And if there’s one thing to add to these suggestions, it’d be a clear versioning convention. Personally, I’m a big fan of the Semantic Versioning.
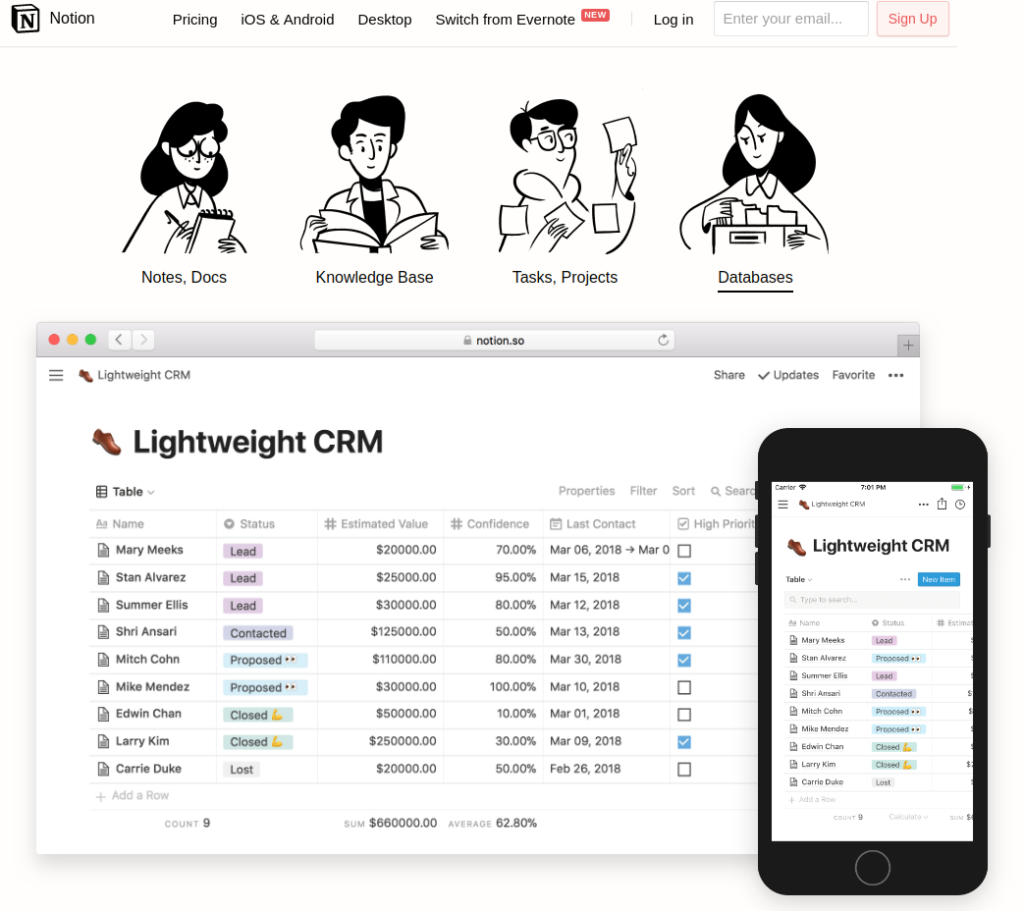
Today I came across yet another interesting application – Notion. It can be a simple note taking app just for yourself, or a collaboration tool for a whole team, with knowledge base, tasks, and project management. There’s also a way to have other types of structured data, like CRM leads, etc.
I wish I had the time to play around with it right now, but I don’t. So I’ll leave it here for the next time.
When it comes to project management, there are many certifications, guidelines, and suggestions all over the web. But it’s often difficult to pick the right one. Some are overly complicated. Others are too simplistic and don’t cover even the whole project lifespan.
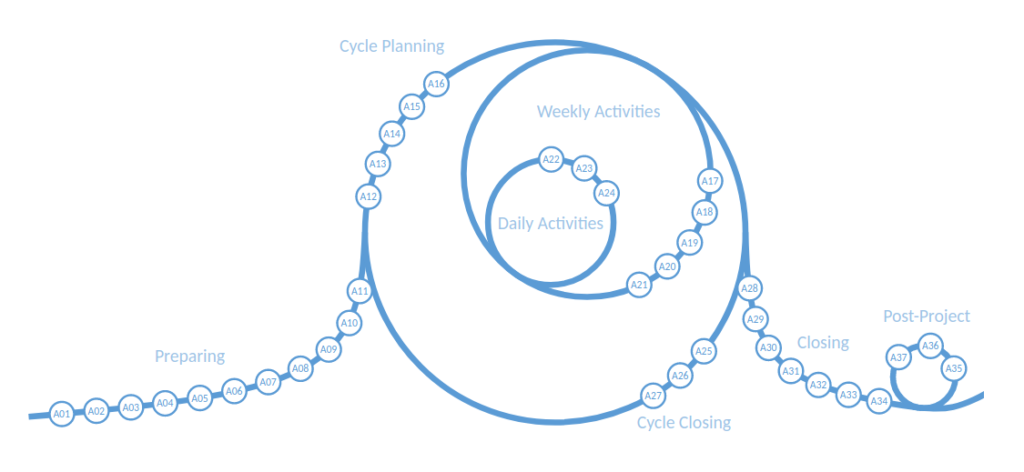
P3.express, however, looks good. It covers the project management process from the early days, when it’s not even clear if the project will proceed at all, to the tasks that need to happen after the project has been fully completed. The whole flow consists of 37 activities in 7 sections, with each one of the activities being well documented and explained.
This one is definitely worth a try. Especially if you ever felt like this:
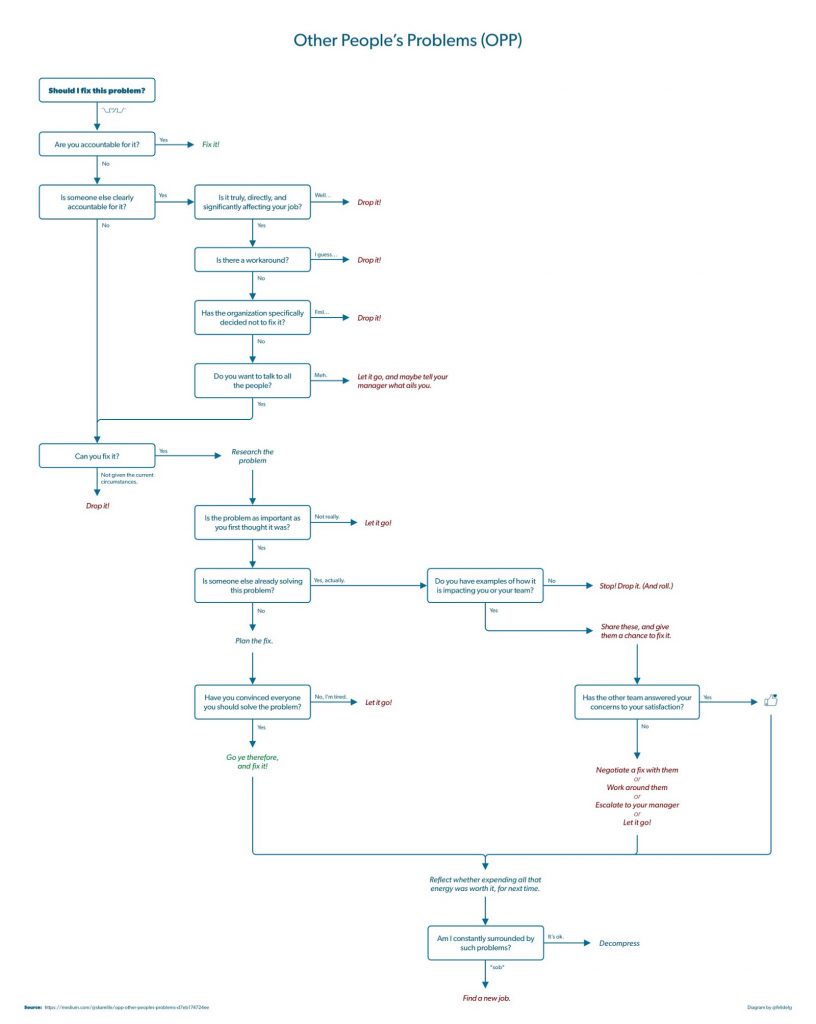
I really liked “OPP (Other People’s Problems)” article which talks about handling of responsibility for things that other people should be responsible for.
If you’re reading this looking for advice, you’re probably a go-getter. You consider yourself a responsible person, who cares deeply about doing things right. Your care may be focused on software and systems, or on people and organizations, or on processes and policies, or all of the above.
This attitude has probably served you well in your career, especially those of you who have been working for a number of years. You’ve been described as having a “strong sense of ownership,” and people admire your ability to think broadly about problems. You try to think about the whole system around a problem, and that helps you come up with robust solutions that address the real challenges and not just the symptoms.
And yet, despite these strengths, you’re often frustrated. You see so many problems, and when you identify those problems, people sometimes get mad. They don’t take your feedback well. They don’t want to let you help fix the situation. Your peers rebuff you, your manager doesn’t listen to you, your manager’s manager nods sympathetically and then proceeds to do nothing about it.
That kind of grinding frustration can wear you down over time. I know, because I’ve been there.
Not only the article describes the problem, but it provides a practical approach to dealing with it.
In the last few years, I was going through a very similar thinking process in my head, but I’m nowhere near the well-defined suggested approach. I wish I read this much earlier in my career. Much much earlier.
This website uses cookies to improve your experience while you navigate through the website. Out of these, the cookies that are categorized as necessary are stored on your browser as they are essential for the working of basic functionalities of the website. We also use third-party cookies that help us analyze and understand how you use this website. These cookies will be stored in your browser only with your consent. You also have the option to opt-out of these cookies. But opting out of some of these cookies may affect your browsing experience.
Necessary cookies are absolutely essential for the website to function properly. This category only includes cookies that ensures basic functionalities and security features of the website. These cookies do not store any personal information.
Any cookies that may not be particularly necessary for the website to function and is used specifically to collect user personal data via analytics, ads, other embedded contents are termed as non-necessary cookies. It is mandatory to procure user consent prior to running these cookies on your website.