Whether you are an experienced shell user, or just a newbie, have a look at this article for a collection of the great tools and examples of how to process text in the shell. It includes all the usual suspects: cat, head, tail, wc, grep, cut, paste, sort, uniq, awk, tr, fold, and sed. Great examples and real life scenarios for each are also provided, with the logic explained and more complex use cases broken down into steps.
Tag: command line
ctop – top-like interface for monitoring Docker containers
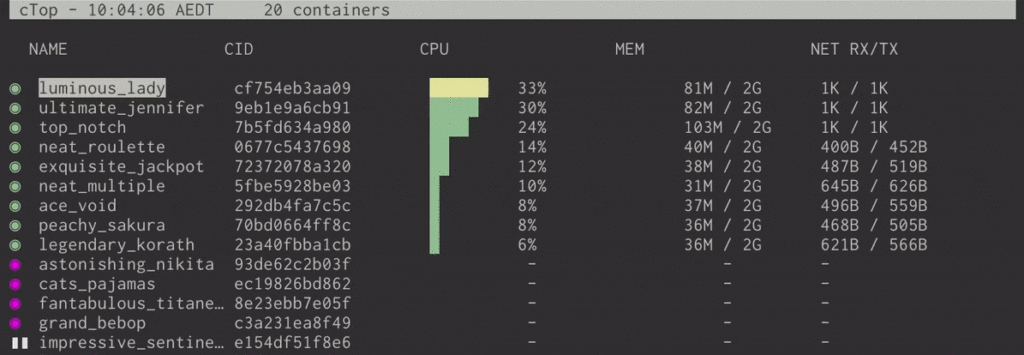
ctop is a very simple, but very useful tool for when you run a number of Docker containers and want to have a top-like overview of their CPU, memory, and network usage.
This article provides more details on how to install, run, and use ctop effectively, including container filtering, single container view, etc.
AWSume: AWS Assume Made Awesome!
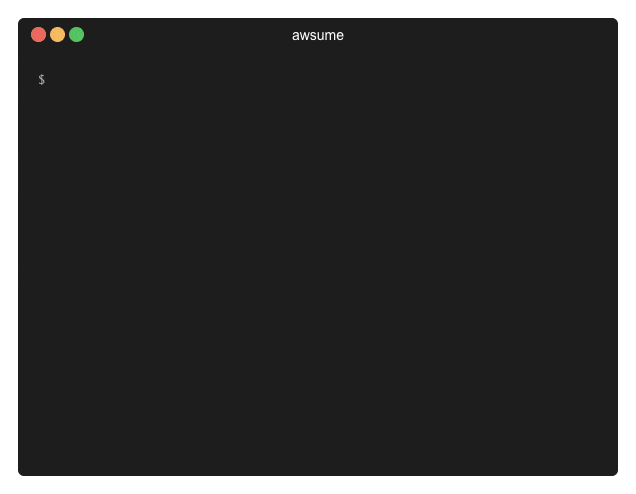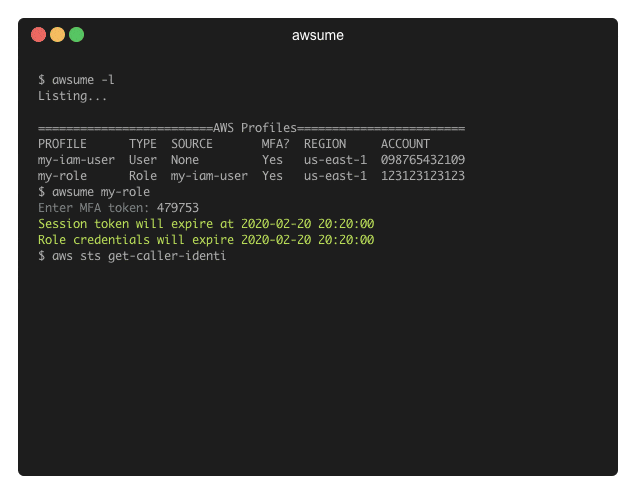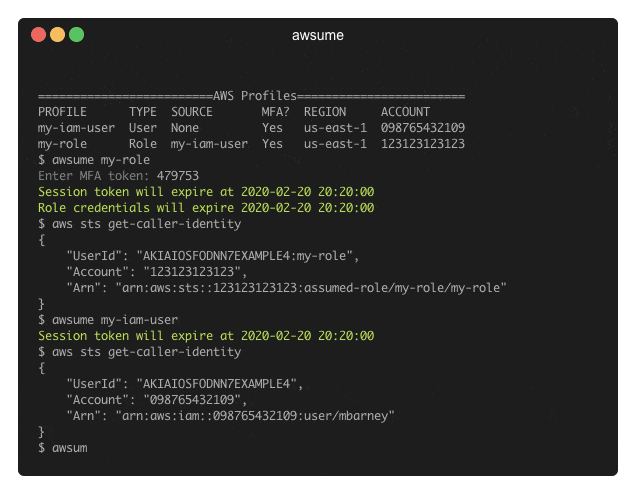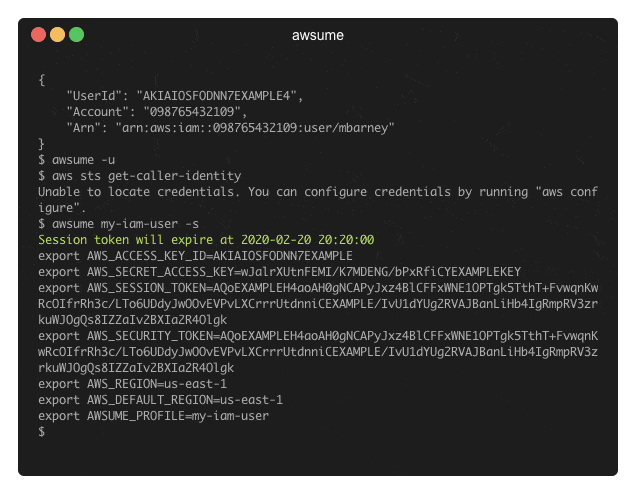
AWSume is a command line tool that makes switching between multiple Amazon AWS profiles really easy and simple.
termtosvg – record terminal sessions as SVG animations
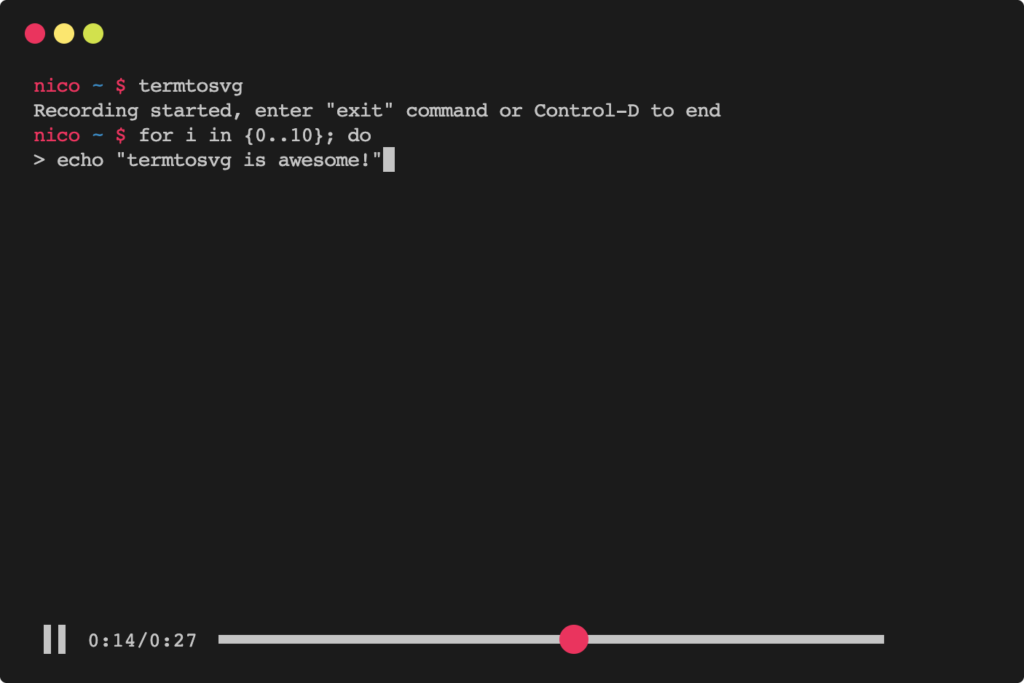
termtosvg (GitHub repo) is a handy little tool that makes recording animated sessions in the terminal as simple as humanly possible. Instead of generating heavy graphics or video animations, this tool creates SVG files, which are a lot smaller and easier. There is also a selection of themes to choose from.
Th resulting SVG files can be used as quick demos and guides in READMEs on GitHub, or as tutorials for your application’s website.
Lazydocker – a simple terminal UI for both docker and docker-compose
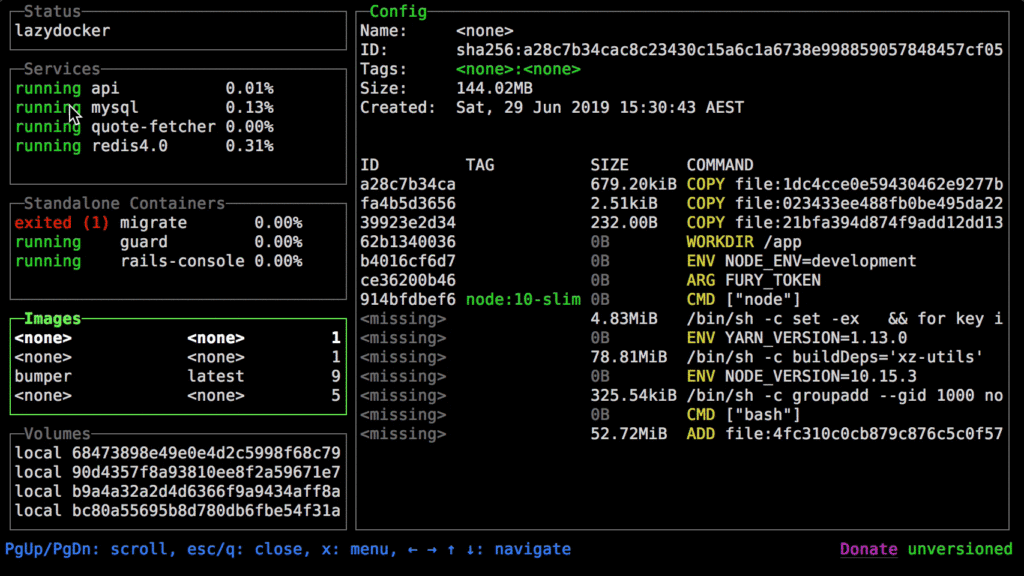
Lazydocker is a simple terminal UI for easier management of Docker. This is particularly useful for new Docker users, but can as well save plenty of keystrokes to the seasoned administrators.