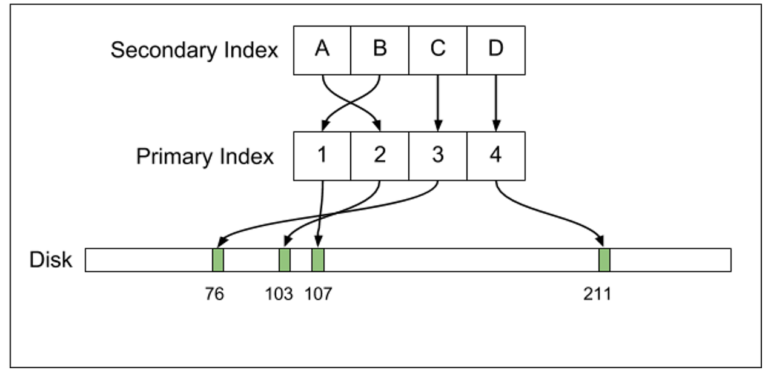
It always amazes me when I randomly come across an article or a blog post precisely on the subject that I’m mulling over in my head – all without searching specifically for the solution or even researching the problem domain. It’s almost like the universe knows what I’m thinking and sends help my way.
“When and where to determine the ID of an entity” is an example of exactly that. Lately, I’ve been working with events in CakePHP a lot. And for one particular scenario, I was considering the beforeSave() event in the model layer, which would trigger some functionality that modifies data in other models. So, having a reference of the current ID would be useful for debugging and logging purposes. But since the current entity hasn’t been saved it, the ID is not there. And that’s where I started thinking about this whole thing and considering where is the right place to generate the ID.
One thing that kind of bothered me on top of the theoretical discussion, was the practical implementation, especially in different frameworks. If I remember correctly, the earlier version of CakePHP framwork, used the presence or absense of the ID in the entity to differentiate between insert and update operations. It might still be true now, but at least there is a way to work around it, as CakePHP now has isNew() method to check if the entity needs to be inserted or updated.