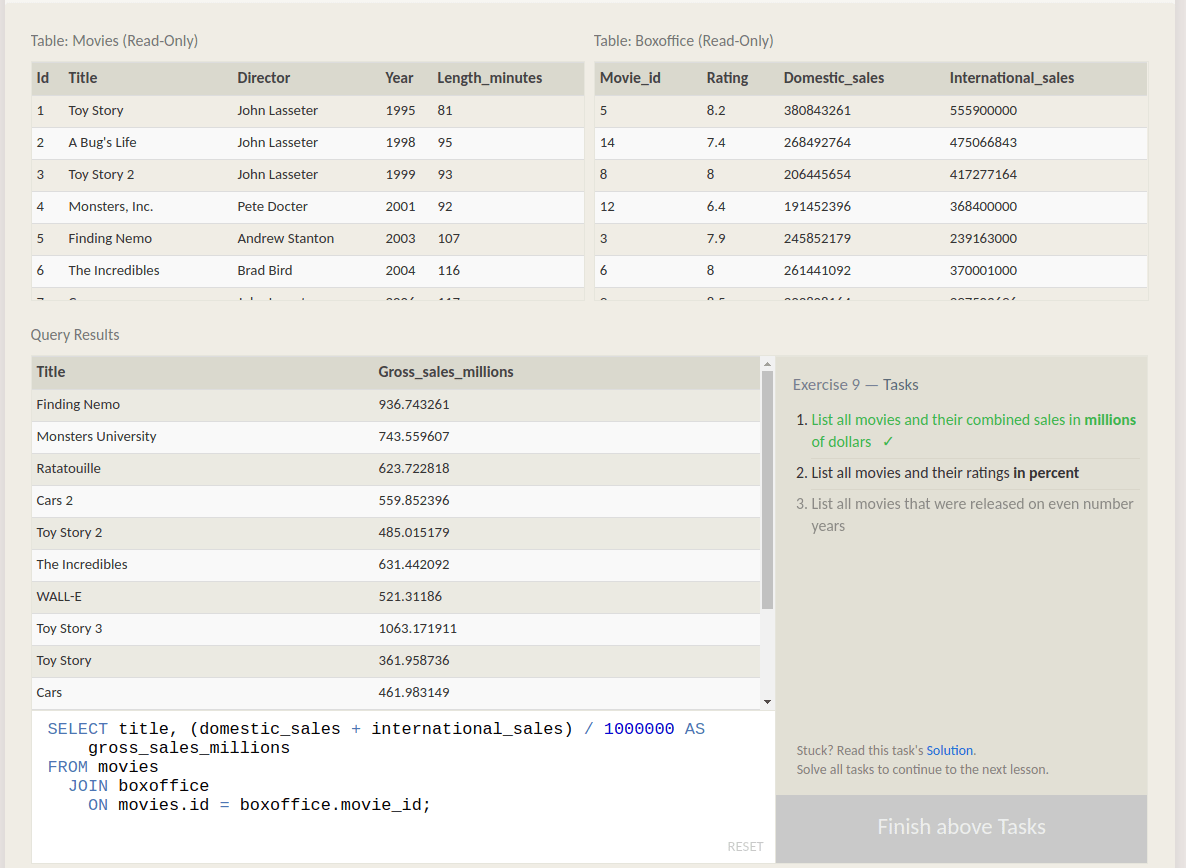
SQLBolt is by far the best SQL tutorial that I’ve ever seen! Yes, I know, it’s a very bold statement. But I promise that it’s true.
With hundreds of books, videos, and other tutorials around, the problem of delivering the understanding of data management, databases, and SQL to regular people still hasn’t been sold. But SQLBolt provides a giant leap forward in this area.
The tutorial starts from the very basics and gets progressively more and more advanced. But this progression is divided into small, very focused chapters. Each chapter provides a brief description of the concept, an example query for the concept, and a set of exercises. The exercises are all interactive, so that you don’t have to install a database or get access to a real one, and you don’t have to trust yourself on correctly solving the tasks. The interactive exercises system marks the problem as solved the moment you type in the correct query.
If you get stuck at any point with any particular exercises, just click on the Solution link nearby, and the tutorial will show you the correct answer. I found this to be a perfect balance between forcing the reader to try things out, but without the annoying delays for those of us who like to skip ahead.
There is really no reason now for anybody at all to learn SQL. SQLBolt is brilliant!