“5 AWS mistakes you should avoid” is a rather opinionated piece on what you should and shouldn’t do with your infrastructure, especially, when using AWS. Here’s an example:
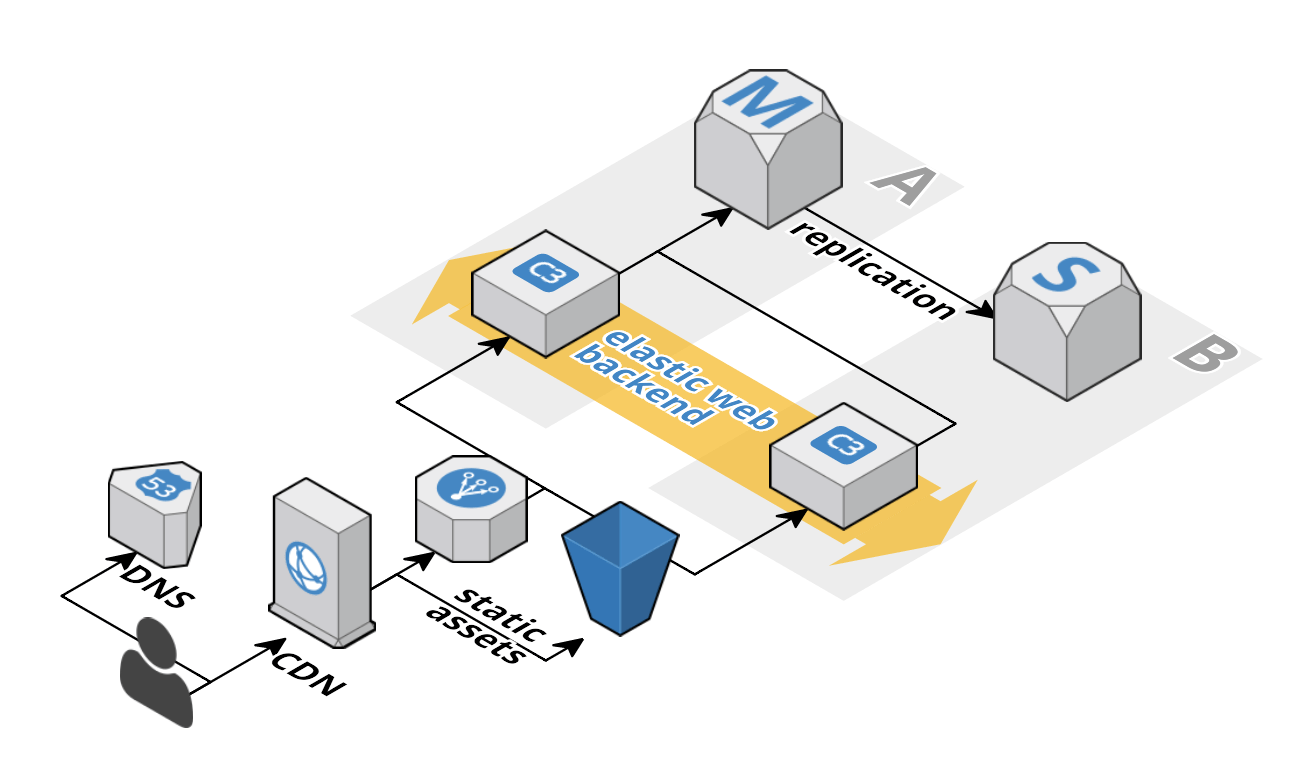
A typical web application consists of at least:
- load balancer
- scalable web backend
- database
and looks like the following figure.
This pattern is very common and if yours look different you should have (strong) reasons.
It’s all good advice in there, but it comes from a very narrow perspective. The “mistakes” are:
- managing infrastructure manually
- not using Auto Scaling Groups
- not analyzing metrics in CloudWatch
- ignoring Trusted Advisor
- underutilizing virtual machines