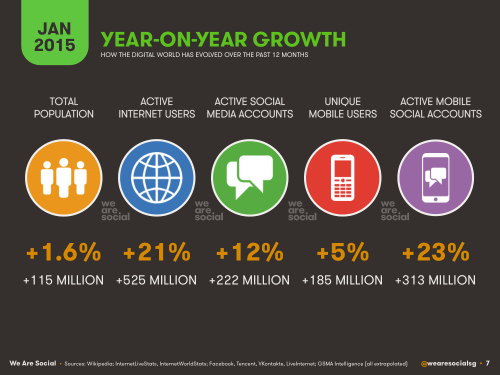
Digital, Social & Mobile in 2015 – a 376 page (!!!) report on how the web changed in the last year.
HTTP/1.1 just got a major update – somehow I missed this last month.
The IETF just published several new RFCs that update HTTP/1.1:
- RFC 7230: Message Syntax and Routing
- RFC 7231: Semantics and Content
- RFC 7232: Conditional Requests
- RFC 7233: Range Request
- RFC 7234: Caching
- RFC 7235: Authentication
- RFC 7236: Authentication Scheme Registrations
- RFC 7237: Method Registrations
- RFC 7238: the 308 status code
- RFC 7239: Forwarded HTTP extension
These documents make the original specification for HTTP/1.1 obsolete. As a HTTP geek, this is a big deal.
RFC 2616, which was written more than 15 years ago, was the specification everybody has implemented, and I suspect many of you occassionally have used as a reference.
Today, a Canary build of Google Chrome removed something kind of important from the browser: the URL.
[…]
Facebook today announced AppLinks, a documented standard for app-to-app linking that has the backing of other big names like Dropbox and Pinterest. While Google is taking the web out of the browser, Facebook is putting the web into apps.
Interesting …
Timely not real-time. Rhythm not random. Moderation not excess. Knowledge not information. These are a few of the many characteristics of the Slow Web. It’s not so much a checklist as a feeling, one of being at greater ease with the web-enabled products and services in our lives.
WI’ve spent most of the last week getting into, around, and out of the issues related to interoperability of Oracle and PHP. Before you start laughing, cursing, and blaming, Oracle wasn’t my choice of the database for this specific project. It’s just the company already had it installed and working for the background, and there needed to be some integration with the front, which is of course MySQL and PHP based.
First thing I do, obviously, is visit PHP.net to check for the prefix of the functions that I need for Oracle. Through out my experience with PHP, that’s about the only thing I need to know to start working with the new database. Oh, and the PHP module installed to provide those functions. Oracle interface for PHP is called is called OCI8. All you need to do now is install the oci8 module.
Here comes the first trouble. oci8 is not provided as a pre-compiled package for Fedora Linux. There is an alternative yum repository – Remi, which has oci8 RPMs, but first of all, the oci8 module is compiled against somewhat outdated Oracle headers (version 10.2.0.4 instead of the latest 11.1.0.1), and it also needs to replace your native PHP and MySQL packages. I tried that, and it sort of worked, but I wasn’t happy. So I got my Fedora packages back and decided that I need to compile oci8 myself.
In order to compile oci8, one needs to download Oracle InstantClient (basic package) and some header files (devel package). These can be downloaded from the Oracle web site, for free, minus the time for the registration. The little trick here is that during oci8 compilation process, the includes are searched from locations which do not include the one from Oracle RPM. I did a simple symlink of the includes folder to where Oracle headers were, and compilation went on just fine. (Hint: otherwise you’ll get a whole lot of Zend related messages and a fatal error). Gladly, I only had to do this path correction on the Fedora 9 machine. My production server with Red Hat Enterprise Linux 5 compiled oci8 without any problems all by itself.
Update: more detailed instructions on the actual installation can be found here and here.
Now that oci8 installed and configured, I spent some time figuring the correct way to specify the DSN. Oracle uses some weirdly name file (tnsnames.ora) in some weird location, but luckily there is a way to go around it. More so, I recommend that you remove tnsnames.ora file altogether, since it can add to your troubles. For example, if you mix spaces and tabs as whitespaces in that file, you are screwed. So, just get rid of it. The way you specify DSN is directly in the PHP script, and you use the syntax like so: “//hostname.or.ip:port/dbname“. Intuitive, I know.
Once you’ll get connected to the server, you have a whole bag of surprises waiting for you. That is if you are too used to working with MySQL. First is the syntax. Oracle is using PL/SQL, so you wipe the dust of from that really old Pascal textbook that you have somewhere. “begin :result := some.procedure.call(:param1, :param2); end;” – that sort of thing. Secondly, you’ll be happy to know that prepared queries are supported. So your workflow will slightly change. Perl programmers will feel more at home here. oci_bind_by_name() and oci_execute() are your friends here. Oh, and while you are at, get familiar with the types of the parameters, because they are important. And don’t forget that you’ll have to bind each and every variable in the query, or get a fatal error. And since you are learning something here, get ready for the oracle errors. The most frequent one you’ll get would be something like “Failed to retreive the error message for ORA-12345”, where 12345 would be a number of the error. So you’ll google for ORA-12345 and ORA-54321 and ORA-XYZZZ a lot. But than you’ll have a wrapper library and you’ll be OK.
Update: as was noted in the comments, PL/SQL is just an option, not a requirement. Also, most of the headaches of the above paragraph could be avoided by using one of the PHP frameworks. I personally haven’t yet tried the framework yet, since I’d like to see things working directly first. Especially since we are not in the test mode only.
The bigger surprise is still waiting for you though. You are very likely to discover that OCI8 implementation for PHP is very slow. And I do mean extremely very slow. I couldn’t believe that it could be slow, so I went into the source code and OMG! It is really slow. The slow part is around fetch_all() against fetch_row(). Basically, it’s always row by row and never all, even if you tell it how many rows you need fetched.
In my case, I have the server a bit far away, and there is a possibility to get many rows back. So even for a simple query with 140 rows in results I was getting 20 seconds execution time. Oracle was serving results fast, the network was OK, machines on both sides were powerful and all, but it was still taking 20 seconds or more.
I am still trying to find the solution to this issue, but so far it seems that the current way I do it will be the way to do it. And the way I do it now is the following. Never ever run direct SQL queries. Everything goes through a stored procedure. The results are returned all in a single row. And that single row has the BLOB (CLOB actually) with all results in one single XML. Fetching works good enough to get it, and then parsing is done with one of the billion XML parsers for PHP.
In my case MiniXML worked pretty good until bigger results started coming in. That’s when I learned an important lesson. MiniXML parses XML with a regular expression. PHP has a couple of settings in the configuration file that limits the size of the memory and recursion during regex parsing – pcre.backtrack_limit and pcre.recursion_limit. If you really want to kill your server, set these to -1 (instead of default 100000) and try a regex against a 1 MB XML file. Enjoy, cause it won’t be long before everything goes down. I didn’t feel like changing from MiniXML so we just implemented some limits in the queries and stored procedures on the Oracle side, and add a few checks in PHP fail rather than crash the system.
So, to some it up, here is my experience with Oracle and PHP from the last week:
One last point in this saga is about Googling. Ask me any question, and I do mean any question, about MySQL. Heck, even PostgreSQL. And the answer is just there, on the first page of Google results. In any human or programming language. For any operating system. You’ll be sorted out and working in less then a minute. Then, try asking even the simplest of the simplest questions about Oracle and PHP. Sometimes you’ll find something. Some other times, you won’t. The overall feeling I have is that not a lot of people are using Oracle with PHP, and those of them who do are in their majority not very happy.
Now I’ve joined the army.