SOAR is an SQL Optimizer and Rewriter. It can help analyse, optimize, and rewrite SQL queries. Don’t get offset by the Chinese documentation as default – there is an English translation.
Here are some of the features:
- Cross-platform support, such as Linux, Mac, and Windows
- Support Heuristic Rules Suggestion
- Support Complicate SQL Indexing Optimize
- Support EXPLAIN analyze for query plan
- Support SQL fingerprint, compress and built-in pretty print
- Support merge multi ALTER query into one SQL
- Support self-config rewrite rules from SQL Rewrite
- Suggestions were written in Chinese. But SOAR also gives many tools, which can be used without understanding Chinese.
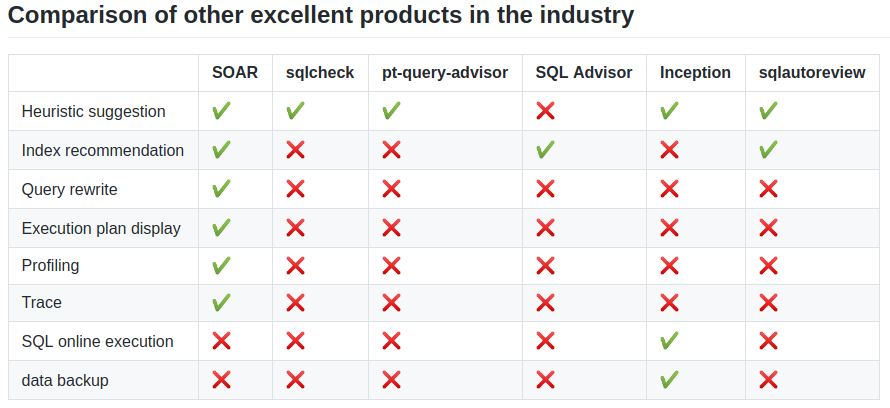
And if you are familiar with the other tools that provide similar functionality, here’s how SOAR compares to them: