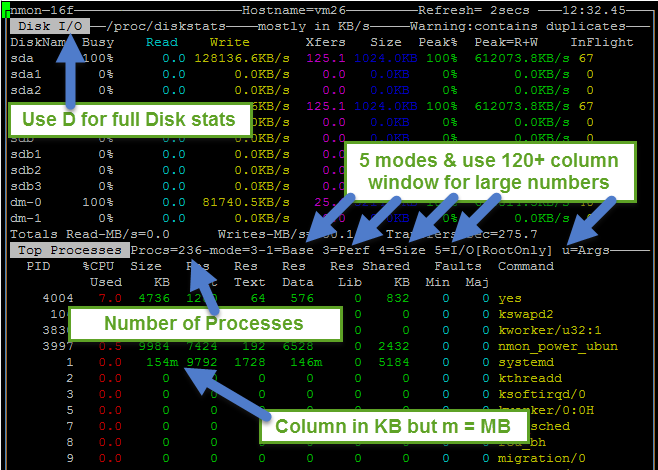
There is probably a gadzillion different ways that you can manage and synchronize you configuration files (aka dotfiles) between different Linux/UNIX boxes – anything from custom symlink scripts, all the way to configuration management tools like Puppet and Ansible. Here are a few options to look at if you are not doing it already.
Personally, I’m using Ansible and I’m quite happy with it, as it allows me to have multiple playbooks (base configuration, desktop configuration, development setup, etc), and do more things than just manage my configuration files (install packages and tools that I often need, setup correct permissions, and more).
Recently, I came across this tutorial from Digital Ocean on how to manage your configuration files with git. Again, there are a few options discussed in there, as even with git, there’s more than one way to do it (TMTOWTDI).
The one that I’ve heard about a long time ago, but completely forgot, and which I think is quite elegant is the approach of separating the working directory from the git repository:
Now, we do things a bit differently. We will start by specifying a different working directory using the core.worktree git configuration option:
git config core.worktree "../../"
What this does is establish the working directory relative to the path of the .git directory. The first ../refers to the ~/configs directory, and the second one points us one step beyond that to our home directory.
Basically, we’ve told git “keep the repository here, but the files you are managing are two levels above the repo”.
I guess, if you stick purely to git, you can offload some of the additional processing, such as permission changes and package installation, into one of the git hooks. Something like post-checkout or post-merge.