Here goes the story of me learning a few new swear words and pulling out nearly all my hair. Grab a cup of coffee, this will take make a while to tell…
First of all, here is a diagram to make things a little bit more visual.
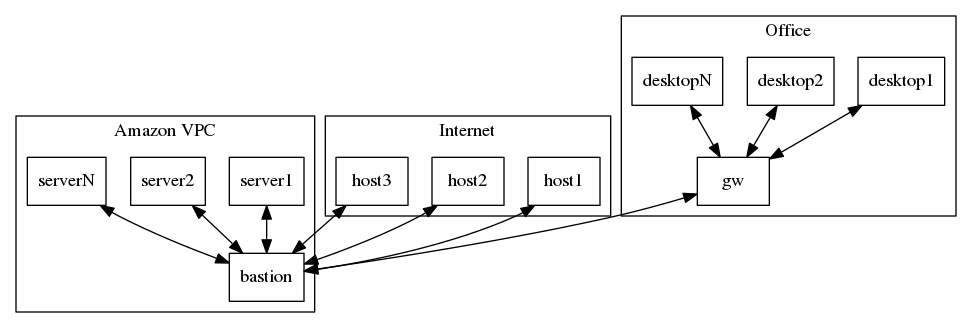
As you can see, we have an office network with NAT on the gateway. We have an Amazon VPC with NAT on the bastion host. And then there’s the rest of the Internet.
The setup is pretty straight forward. There are no outgoing firewalls anywhere, no VLANs, no network equipment – all of the involved machines are a variety of Linux boxes. The whole thing has been working fine for a while now.
A couple of weeks ago we had an issue with our ISP in the office. The Internet connection was alive, but we were getting extremely high packet loss – around 80%. The technician passed by, changed the cables, rebooted the ADSL modem, and we’ve also rebooted the gateway. The problem was fixed, except for one annoying bit. We could access all of the Internet just fine, except our Amazon VPC bastion host. Here’s where it gets interesting.
Consider the following:
- Amazon VPC bastion host was perfectly available from all Internet hosts.
- Amazon VPC bastion host was perfectly available from the gateway host.
- All Internet hosts were perfectly available from all office computers.
- Amazon VPC bastion host was pingable from all office computers … but
- Amazon VPC service (ssh, https, etc) were unavailable from all office computers (“Connection timeout” errors).
The following were checked and confirmed:
- Office gateway NAT configuration was fine.
- Amazon VPC bastion NAT configuration was fine.
- No outgoing firewall was present on the office gateway.
- Incoming firewall on the Amazon VPC bastion was fine.
- All necessary services on Amazon VPC bastion (ssh, https, etc) were working fine.
And yet it was impossible to SSH into the bastion host from any computer on the office network. The outgoing IP address of the office gateway was the same as the outgoing IP of the machines going through NAT. The traceroute was the same from the office gateway and the machines on the office network…
Let’s where lots of swearing and hair pulling happened.
Until I gave up and called for help. My younger brother, who is a sysadmin genius, jumped on the case. Within the first hour of checking everything and troubleshooting the issue, he confirmed that I wasn’t a complete idiot – all the settings looked right and it should be working.
A few more hours later, with tcpdump in his hands, he managed to locate and fix the problem. The solution was very simple. Add the following line to the /etc/sysctl.conf of the Amazon VPC bastion host (running Amazon Linux AMI 2015.09):
net.ipv4.tcp_tw_recycle=0
I’ll leave it to his discretion to explain how he found the problem. How does the fix work? Well, here is a handy article – “Copying with the TCP TIME-WAIT state on busy Linux servers“. I read the article twice, and the best way to describe how I understand it is with this scene from the IT Crowd TV series – season 1, episode 1, Jen zones out on Moss’ explanation:
Gladly, the article provides the “too long; didn’t read” summary:
TL;DR: Do not enable
net.ipv4.tcp_tw_recycle.
So, for all of you future generations, I hope you’ll find this useful.
Huge thanks goes to my brother for solving the issue, Vincent Bernat for posting the article, and Guinness for providing the best sanity medication worldwide.
One thought on “WTF with Amazon and TCP”