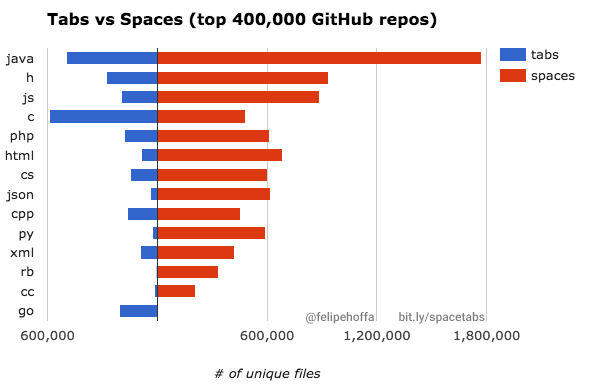
Here is an interesting bit of research – do people prefer tabs or spaces when programming the most popular languages?
Tabs or spaces. We are going to parse a billion files among 14 programming languages to decide which one is on top.
The results are not very surprising and somewhat disappointing (for all of us, tab fans):

As far as PHP goes, I’m sure the choice of spaces has to do with the PSR-2 coding style guide, which states:
Code MUST use 4 spaces for indenting, not tabs.
On a more technical note, I think this is also related to the explosion of editors and IDEs in the recent years, which, as good as they are, aren’t as good as Vim. Vim allows for a very flexible configuration, where your code can be formatted and re-formatted any way you like, making tabs or spaces a non-issue at all.
Regardless of the results of the study, what’s more interesting is the method and tools used. I’ve had my eye on the Google Big Query for a while now, but I’m too busy these days to give it a try. The article gives a few insights, into how awesome the tool is. 1.6 terabytes of data processed in 864.6 seconds:
That query took a relative long time since it involved joining a 190 million rows table with a 70 million rows one, and over 1.6 terabytes of contents. But don’t worry about having to run it, since I left the result publicly available at [fh-bigquery:github_extracts.contents_top_repos_top_langs].
and:
Analyzing each line of 133 GBs of code in 16 seconds? That’s why I love BigQuery.
If you enjoyed this article, also have a look at “Analyzing GitHub issues and comments with BigQuery“, which works with a similar-sized data, trying to figure out how to write bug reports and pull request comments, so that they would be acted upon faster.