Vue CloudWatch Dashboard – a simple live dashboard for Amazon CloudWatch metrics.
Vue CloudWatch Dashboard – a simple live dashboard for Amazon CloudWatch metrics.
Tag: monitoring
PHP application logging with Amazon CloudWatch Logs and Monolog
 AWS Developer Blog ran this post a while back – “PHP application logging with Amazon CloudWatch Logs and Monolog“, in which they show how to use Monolog and Amazon CloudWatch together in any PHP application. It goes beyond a basic configuration of connecting the two, all the way into setting up log metrics, etc.
AWS Developer Blog ran this post a while back – “PHP application logging with Amazon CloudWatch Logs and Monolog“, in which they show how to use Monolog and Amazon CloudWatch together in any PHP application. It goes beyond a basic configuration of connecting the two, all the way into setting up log metrics, etc.
Handling Amazon SNS messages with PHP, Lumen and CloudWatch
Gonzalo Ayuso throws a few snippets of code in the blog posts title “Handling Amazon SNS messages with PHP, Lumen and CloudWatch“, which shows how to work with Amazon SNS (Simple Notifications Service) and Amazon CloudWatch (cloud and network monitoring solution) from PHP. The examples are based on the Lumen micro-framework, which is basically a stripped down Laravel.
Replaying JavaScript errors from the userland
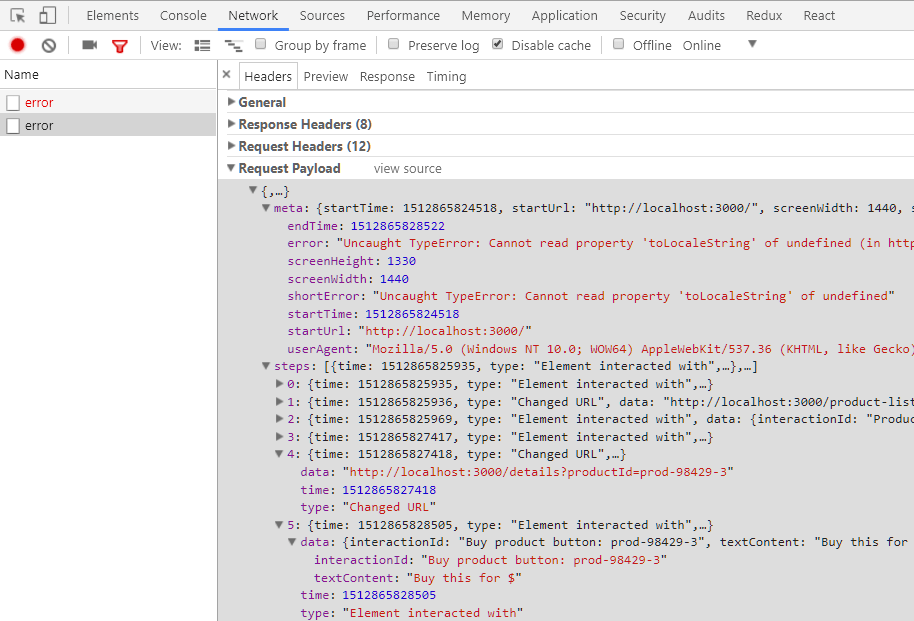
I came across this interesting dive into monitoring, troubleshooting, and replaying JavaScript errors from the userland – “A user encounters a JavaScript error. You’ll never guess what happens next!!“.
This is not something immediately applicable for my projects at work, but gives me a lot to think about.
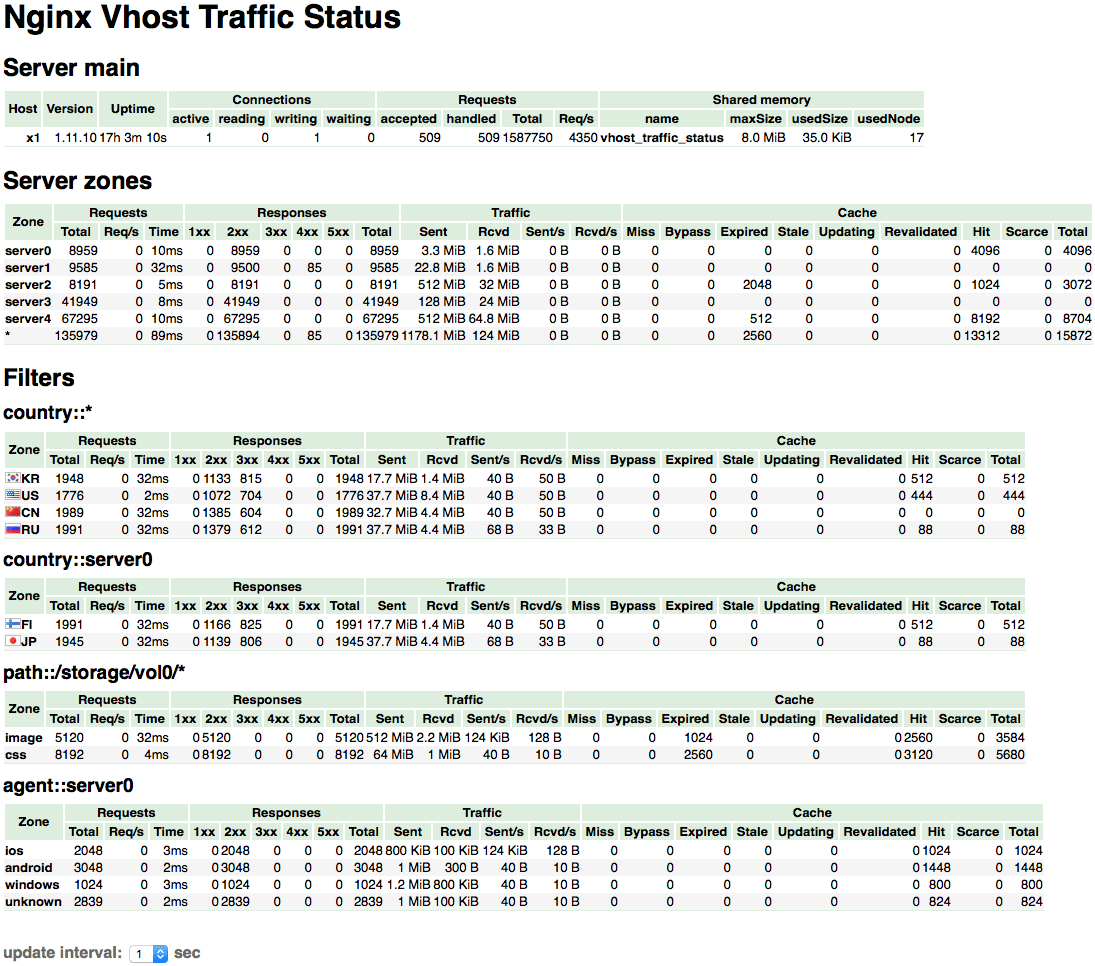
nginx-module-vts – Nginx virtual host traffic status module
nginx-module-vts is a handy Nginx module for those who run complex Nginx configurations, with multiple servers, virtual hosts, caches, etc. Here’s an example partial screenshot of the output.