One of the things that people on the web do is follow each other. Reading blog posts, watching favorite video clips, stare at shared photos, reply to comments, get status updates, and so on and so forth.
In the previous years, the number of people who were online was much smaller. And they weren’t publishing as much as they do now. Everyone and their dog has a blog. Pictures and videos are flying around. Playlists and favorite songs are shared. Micro-blogging is blossoming. How can anyone follow all that? Well, RSS, of course, is one of the common answers.
But, RSS has its share of problems. It is still too technical to be used by many people. Good tools are a few. And grouping things around people isn’t much fun yet. Also, feed discovery is still an issue (from a person’s point of view, not the aggregator point of view).
FriendFeed.com web service recently went public and solved a few problems. It starts off with feed discovery. When you register and login, you can easily specify all the places that you publish at – blog, Flickr photostream, del.icio.us bookmarks, LinkedIn profile, Twitter, and so on and so forth. This way, when somebody is interested in following you up, he or she will just need to subscribe to you once and get all the stuff from everywhere where you publish. This is cool.
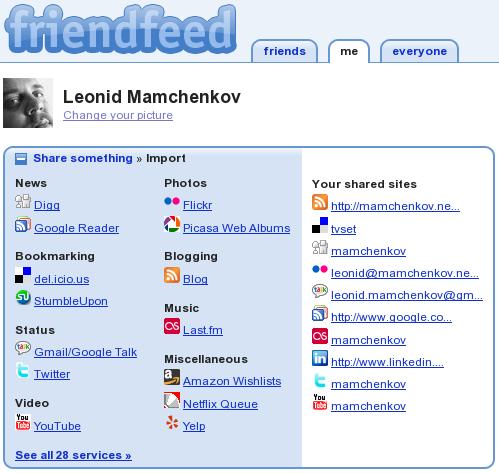
Another problem that FriendFeed solves is the problem of virtual people. In social networks, it is often that you can’t follow a person who hasn’t registered yet. You can invite them in, wait for them to join, and then be notified when they joined. But it is often impossible to follow people who decided not to join the network. In FriendFeed, you can create “imaginary friends”. This way, you can group people and sources in any way you like best.  This is priceless.
For example, you can create an imaginary friend for a person who hasn’t registered, and you can assign a blog and a Flickr photostream to him. Or, you can create an imaginary friend for a real person, who even registered, but who publishes so much that you can’t take it. Instead of following of their stuff, you just pick things that you are interested in (say Twitter messages and blog, but not Flickr and YouTube) and link those to your imaginary friend.
With this functionality, following topics or events becomes extremely easy. If you are interested in kebab cooking ,or in Cyprus switching to Euro, or anything else for that matter, you can create an imaginary friend for the topic and assign it blogs, Google Reader shared items, Picasa photos, or whatever else is supported. There is a lot of potential in here.
Another thing that FriendFeed does right is presentation of data. There are links to original sources whenever possible, and there are thumbnails for whatever possible. Also, people have avatars, which makes it very easy to distinguish who is who and who published what.
And if all that wasn’t enough, you can subscribe to updates via email. Which means that you can really improve your productivity while still following a whole lot of sources. No need to run around the web looking for updates. No need to interrupt your work flow to see if there is a reply to your comment. You just get used to getting back at all the updates once a day in a brief, but nicely looking digest form, and that’s it!
FriendFeed is a really nice services which a lot of people were waiting for and which they will appreciate now that it is finally here. Oh, and just in case, here is the link to my FriendFeed profile.