If you woke up today and found that most of your PHP projects’ and libraries’ tests break and fail, I have news for you: you are doing something wrong. How do I know? Because I was doing something wrong too…
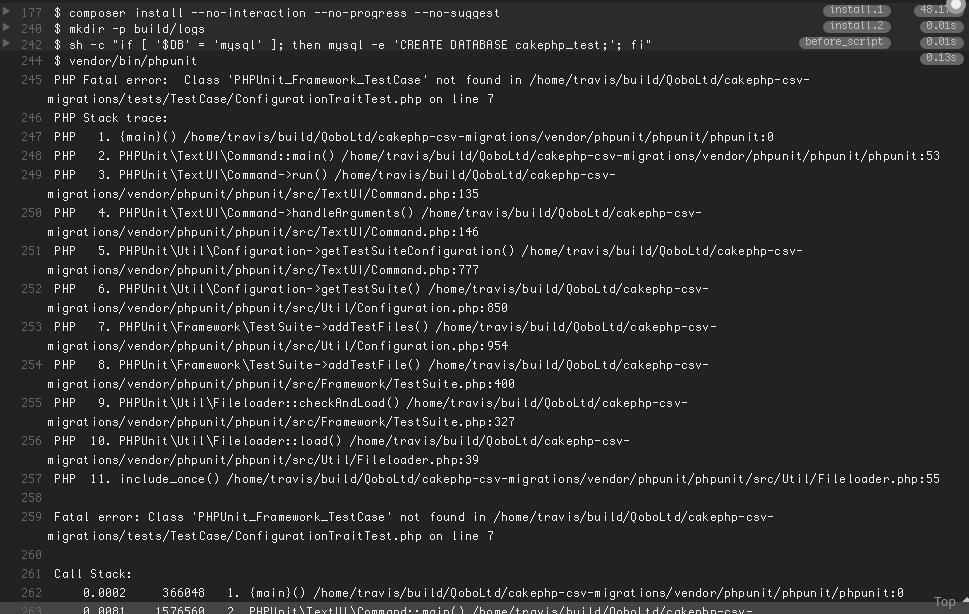
First of all, let me save you all the extra Googling. Your tests are failing, because a new major version of PHPUnit has been released – version 6.0.0. This version drops support for PHP 5 and, using the opportunity of the major version bump, gets rid of a bunch of stuff that was marked obsolete earlier.
But why does it fail, you ask. Well, because PHPUnit is included in pretty much every composer.json file out there. And the way it’s included is almost always is this:
"require-dev": {
"phpunit/phpunit": "*",
}
PHPUnit being a part of pretty much every composer.json file, is probably the reason why people want to be much more relaxed with the used version, than with any other component of the system. That’s usually good. Until it breaks, much like today with the release of the PHPUnit 6.
How can you fix the problem? Well, the quickest and the easiest solution is to update the composer.json with “^5.0” instead of “*”. This will prevent PHPUnit from upgrading until you are ready.
While you are doing it, check the other dependencies and make sure that none of them are using the asterisk either. Because, chances are, the exact same problem will happen later with those too.
The only difficult bit about this whole situation is the correlated drop for the PHP 5 support. Yes, sure, it has reached its end of life, but there are still a lot of projects and environments that require it, and will require it for a lonweg time.
As you are the master of your code and dependencies, other people are of their own. So you can’t really control when each of your dependencies will update the requirement for the PHPUnit 6, or any other tool that requires PHP 7.
On the bright side, major releases of PHP don’t happen that often, so this shouldn’t be the frequent problem.