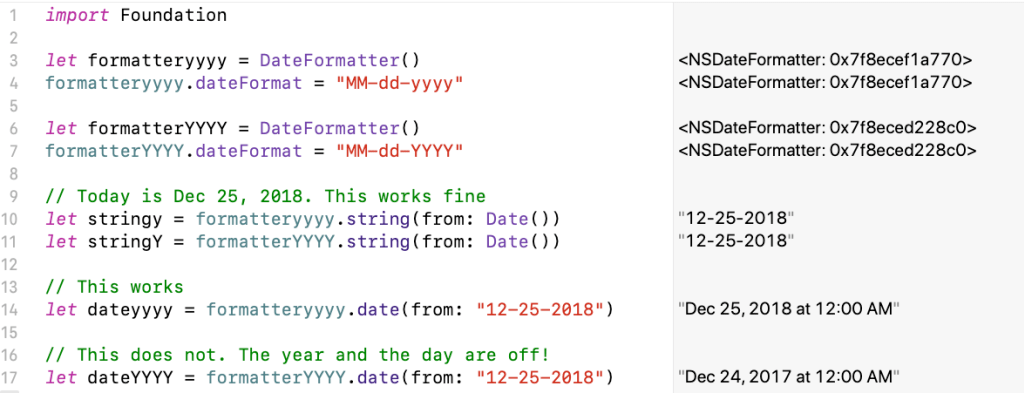
“Dotfile madness” is an excellent look at the problem of hidden data and configuration files that seem to be multiplying lately in the users’ home directories:
We are no longer in control of our home directories.
My own home directory contains 25 ordinary files and 144 hidden files. The dotfiles contain data that doesn’t belong to me: it belongs to the programmers whose programs decided to hijack the primary location designed as a storage for my personal files. I can’t place those dotfiles anywhere else and they will appear again if I try to delete them. All I can do is sit here knowing that in the darkness, behind the scenes, they are there. Waiting in silence. Some of those programmers decided to additionally place some normal files and directories in the same place. Those are clearly visible every time I executelsin my home directory.
While there is no easy centralized solution to this problem, as each application’s developer decides for himself, the article proposes a better way of doing things, reminding us about the XDG Base Directory Specification. This spec allows for a much finer control of where things go via the XDG_* environment variables.
Nice one!