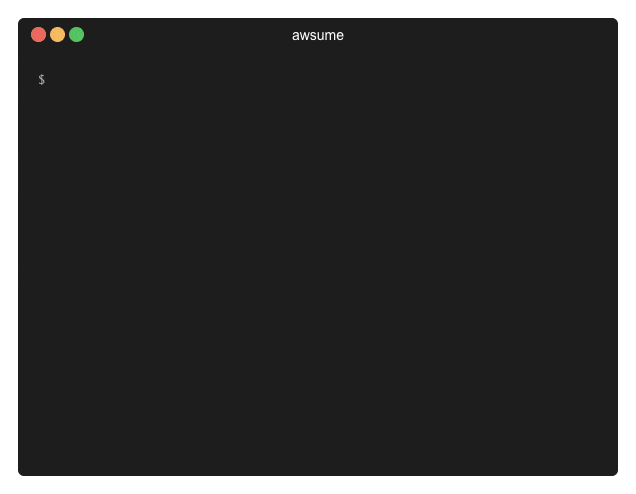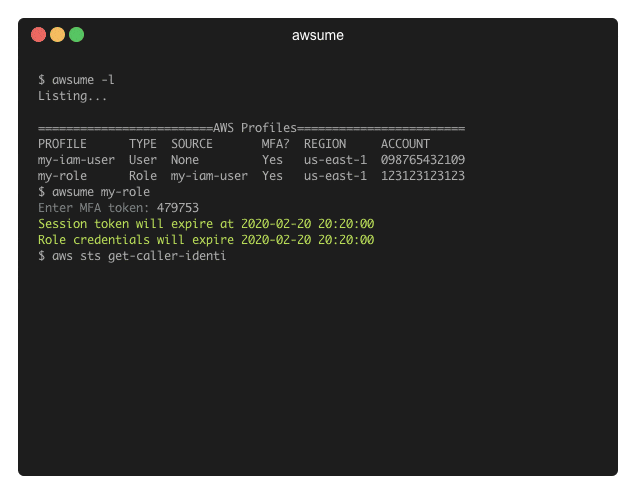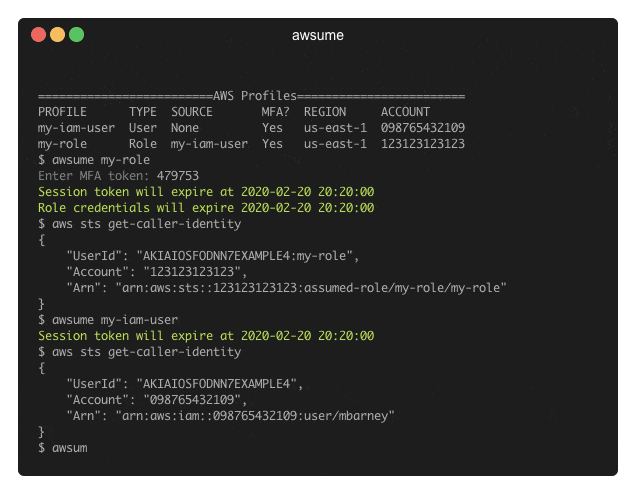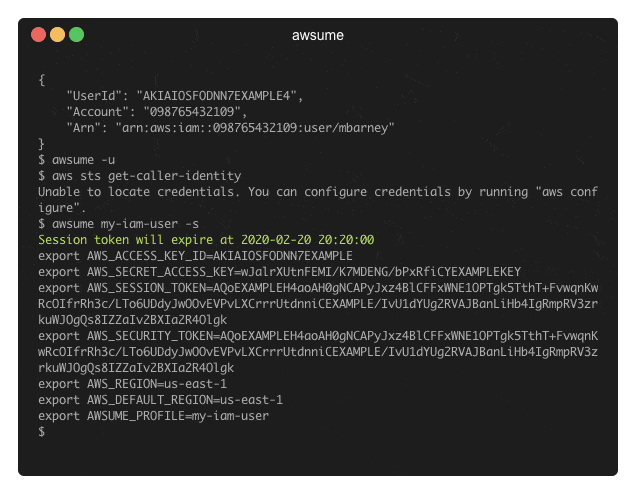
AWSume is a command line tool that makes switching between multiple Amazon AWS profiles really easy and simple.
AWSume is a command line tool that makes switching between multiple Amazon AWS profiles really easy and simple.
Location: THE SHIP INN BAR/RESTAURANT
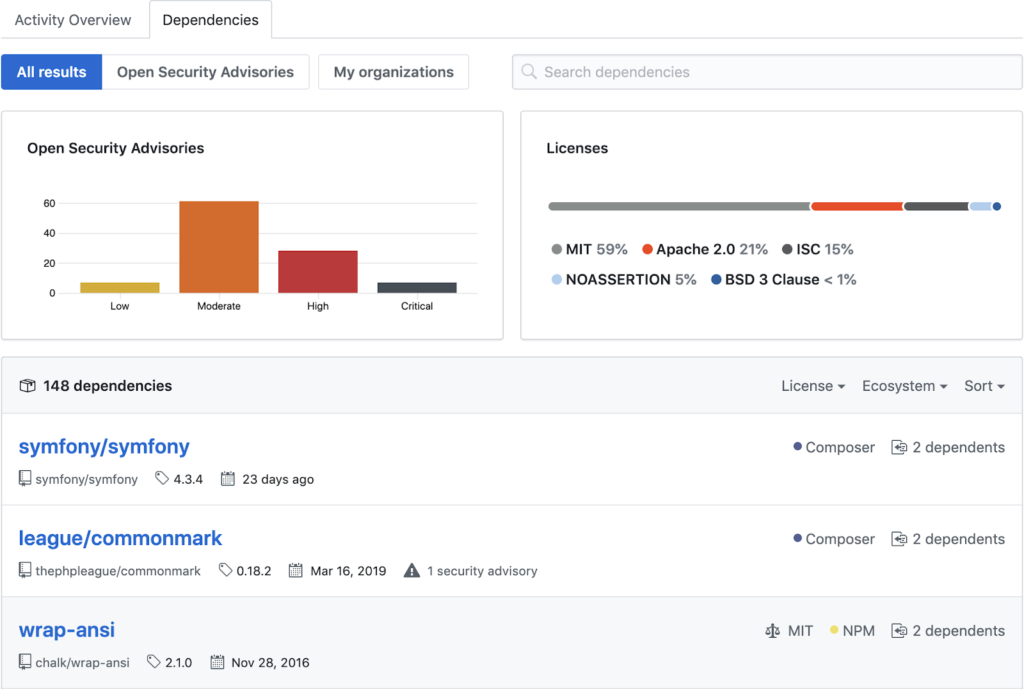
Here are some great news from GitHub: Dependency graph support is now available for PHP repositories with Composer dependencies.
You may see security alerts on your repositories as dependency graph support rolls out. When there’s a published vulnerability on any of the Composer dependencies that your project lists in
composer.jsonandcomposer.lockfiles, GitHub will send you an alert including email or web notifications, depending on your preferences.
These now work for both public and private repositories, and repository admins can enable or disable the features as needed.
“How HTTPS Works in 10 Minutes” is a simple, high-level overview of how HTTPS works. It doesn’t dive into too much detail or heavy math. But it does cover the main stages of how the connection is established, verified, and encrypted. These are the stages that are covered:
