Amazon Machine Learning Blog announces some very significant improvements to the Amazon Rekognition – their service for image and video analysis. These particular changes are improving the face recognition technology.
Amazon Machine Learning Blog announces some very significant improvements to the Amazon Rekognition – their service for image and video analysis. These particular changes are improving the face recognition technology.
“Face detection” tries to answer the question: Is there a face in this picture? In real-world images, various aspects can have an impact on a system’s ability to detect faces with high accuracy. These aspects might include pose variations caused by head movement and/or camera movements, occlusion due to foreground or background objects (such as faces covered by hats, hair, or hands of another person in the foreground), illumination variations (such as low contrast and shadows), bright lighting that leads to washed out faces, low quality and resolution that leads to noisy and blurry faces, and distortion from cameras and lenses themselves. These issues manifest as missed detections (a face not detected) or false detections (an image region detected as a face even when there is no face). For example, on social media different poses, camera filters, lighting, and occlusions (such as a photo bomb) are common. For financial services customers, verification of customer identity as a part of multi-factor authentication and fraud prevention workflows involves matching a high resolution selfie (a face image) with a lower resolution, small, and often blurry image of face on a photo identity document (such as a passport or driving license). Also, many customers have to detect and recognize faces of low contrast from images where the camera is pointing at a bright light.
With the latest updates, Amazon Rekognition can now detect 40 percent more faces – that would have been previously missed – in images that have some of the most challenging conditions described earlier. At the same time, the rate of false detections is reduced by 50 percent. This means that customers such as social media apps can get consistent and reliable detections (fewer misses, fewer false detections) with higher confidence, allowing them to deliver better customer experiences in use cases like automated profile photo review. In addition, face recognition now returns 30 percent more correct ‘best’ matches (the most similar face) compared to our previous model when searching against a large collection of faces. This enables customers to obtain better search results in applications like fraud prevention. Face matches now also have more consistent similarity scores across varying lighting, pose, and appearance, allowing customers to use higher confidence thresholds, avoid false matches, and reduce human review in applications such as identity verification. As always, for use cases involving civil liberties or customer sentiments, where the veracity of the match is critical, we recommend that customers use best practices, higher confidence level (at least 99%), and always include human review.
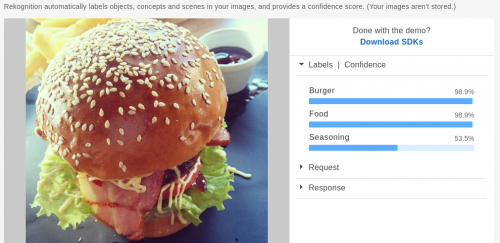
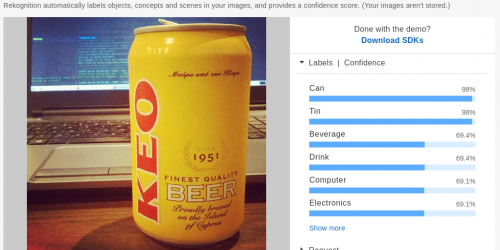
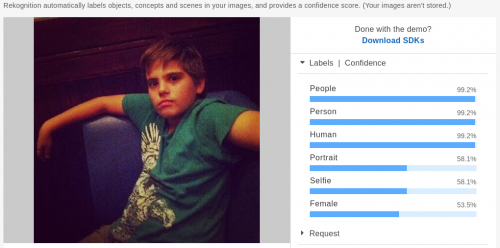
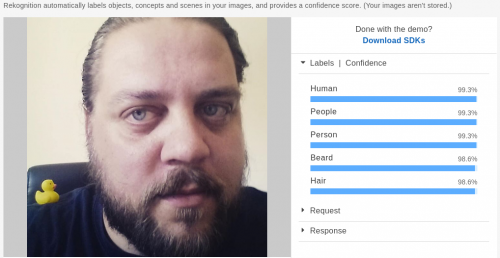
Have a look at their blog post for some examples of what the machine can recognize as a face. Some of these are difficult enough to treat many humans, I think.