Once in a while a seemingly straightforward article turns into a goldmine of links and resources. This happened to me today with this one – “Reading postmortems“.
Not only this article itself is a very nice roundup of common sources for system failures, but it also links to a couple of awesome references:
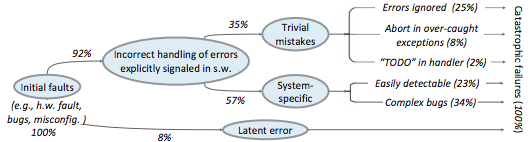
- Simple Testing Can Prevent Most Critical Failures: An Analysis of Production Failures in Distributed Data-Intensive Systems. This is both a talk and a paper.
- danluu/post-mortems – a GitHub repository with a collection of publicly available postmortems from a variety of organizations, like Google, Amazon, Facebook, NASA, GitHub, and more.
If you still have no idea what postmortem is, Wikipedia explains.