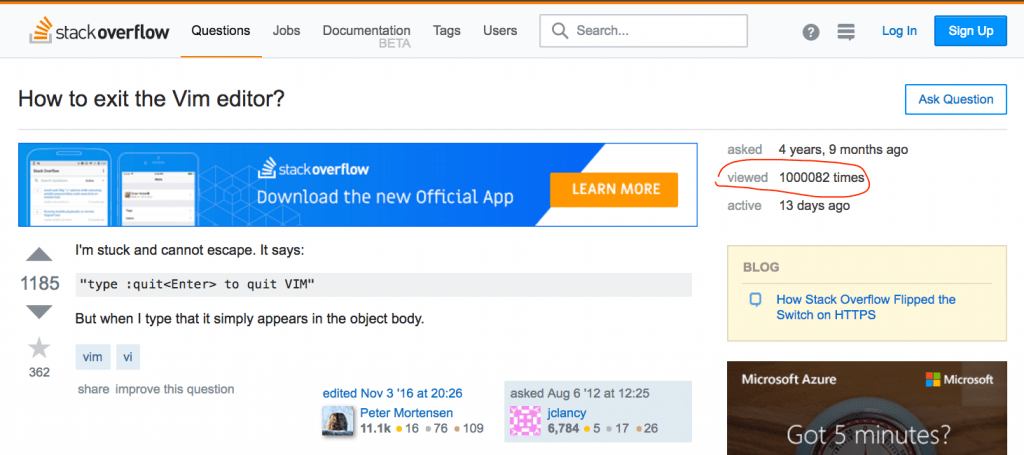
Here’s an outage postmortem from the recent StackOverflow downtime. It just shows you how easy it is to break things, even they were built by some of the smartest people around. Programming is touch and there is no way around it.
Technical Details
The regular expression was: ^[\s\u200c]+|[\s\u200c]+$ Which is intended to trim unicode space from start and end of a line. A simplified version of the Regex that exposes the same issue would be \s+$ which to a human looks easy (“all the spaces at the end of the string”), but which means quite some work for a simple backtracking Regex engine. The malformed post contained roughly 20,000 consecutive characters of whitespace on a comment line that started with — play happy sound for player to enjoy. For us, the sound was not happy.
If the string to be matched against contains 20,000 space characters in a row, but not at the end, then the Regex engine will start at the first space, check that it belongs to the \s character class, move to the second space, make the same check, etc. After the 20,000th space, there is a different character, but the Regex engine expected a space or the end of the string. Realizing it cannot match like this it backtracks, and tries matching \s+$ starting from the second space, checking 19,999 characters. The match fails again, and it backtracks to start at the third space, etc.
So the Regex engine has to perform a “character belongs to a certain character class” check (plus some additional things) 20,000+19,999+19,998+…+3+2+1 = 199,990,000 times, and that takes a while. This is not classic catastrophic backtracking (talk on backtracking) (performance is O(n²), not exponential, in length), but it was enough. This regular expression has been replaced with a substring function.