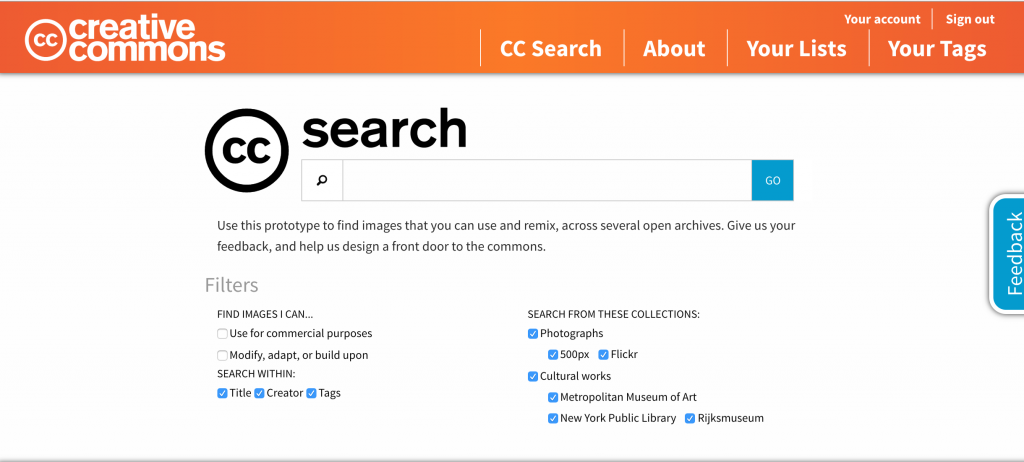
This title almost sounds stupid, right? I mean, pretty much everyone who has ever been online knows how to Google. Even kids.
But I promise you it’s not. Searching for quick and simple stuff – yes, sure, is easy. But not many people I’ve met know how to use even Google’s advanced search options (despite there being a gadzillion articles online), let alone other search engines. Searching for something non-trivial, like research papers and books, is even trickier.
Hence the Internet Search Tips. Here’s the intro from the author:
Over time, I developed a certain google-fu and expertise in finding references, papers, and books online. Some of these tricks are not well-known, like checking the Internet Archive (IA) for books. I try to write down my search workflow, and give general advice about finding and hosting documents.