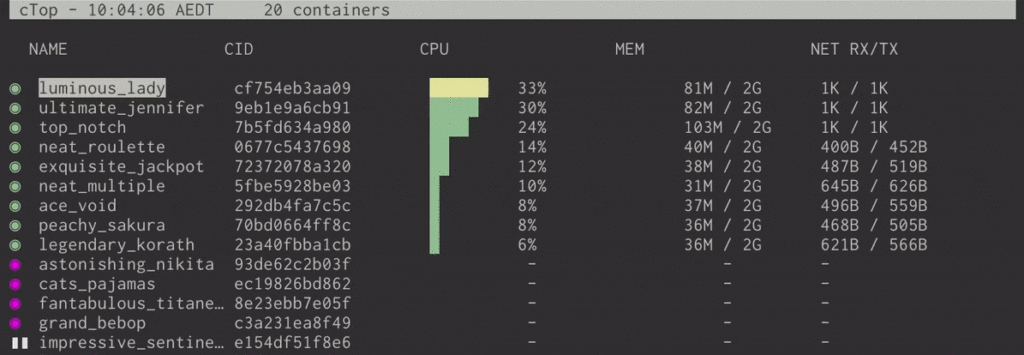
ctop is a very simple, but very useful tool for when you run a number of Docker containers and want to have a top-like overview of their CPU, memory, and network usage.
This article provides more details on how to install, run, and use ctop effectively, including container filtering, single container view, etc.