As a heavy user of Amazon Web Services, I often find myself in deep discussions about Amazon company, its broad portfolio of brands, the way they make money, and their strategy going forward.
Admittedly, that’s not an easy area to understand, let alone explain or argue about. That’s why I really enjoyed this video. It is oversimplifying a lot of things, but it does a nice job of shedding some light on what is going now, where it is heading, and how it is similar and different to some other companies.
“Most of What You Read on the Internet is Written by Insane People” is a nice little roundup of statistics from a several large sites like Wikipedia, Amazon, YouTube, Reddit, etc. These stats support the viewpoint that on these huge sites, most of the content is generated by a very small number of users.
Inequalities are also found on Wikipedia, where more than 99% of users are lurkers. According to Wikipedia’s “about” page, it has only 68,000 active contributors, which is 0.2% of the 32 million unique visitors it has in the U.S. alone. Wikipedia’s most active 1,000 people — 0.003% of its users — contribute about two-thirds of the site’s edits. Wikipedia is thus even more skewed than blogs, with a 99.8–0.2–0.003 rule.
Some of these numbers are staggering. And the people who do the work, are indeed – insane. Not medically, but by deviation of how much they do and for how long, as compared to the rest of the user base, or even population.
By the way, pretty much all posts in this very blog have been written by one person. Me. Almost 10,000 posts over 19 years. So yes, I’m also probably a little bit insane.
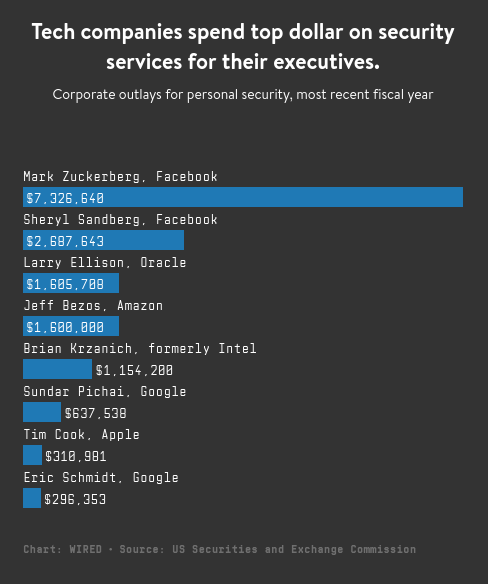
There’s plenty of talk about security when it comes to giant technical companies, like Google, Facebook, Amazon, and Apple. But that’s all usually from the perspective of the software security and end-user privacy. Here’s a different perspective on the subject – “The Millions Silicon Valley Spends on Security for Execs“.
Apple’s most recent proxy statement, filed earlier this month, shows the company spent $310,000 on personal security for CEO Tim Cook. But that’s a fraction of other tech giants’ expenditures. Amazon and Oracle spent about $1.6 million each in their most recent fiscal years to protect Jeff Bezos and Larry Ellison, respectively, according to documents filed with the US Securities and Exchange Commission. And Google’s parent company, Alphabet, laid out more than $600,000 protecting CEO Sundar Pichai and almost $300,000 on security for former executive chair Eric Schmidt. In 2017, Intel spent $1.2 million to protect former CEO Brian Krzanich. Apple, Google, Intel, and Oracle declined to comment; Amazon did not respond to a request for comment. Facebook CEO Mark Zuckerberg was the costliest executive to protect; Facebook spent $7.3 million on his security in 2017, and last summer the company told investors that it anticipated spending $10 million annually.
Well, that’s pretty impressive in terms of money! But do they need it really? They do, at least, to some degree:
While Silicon Valley firms haven’t disclosed many threats to the safety of their executives or offices, they have good reason to take precautions. In December, Facebook evacuated its headquarters after the company received a bomb threat. Last year an unhappy YouTube user entered the company’s San Bruno, California, headquarters and shot three employees before killing herself. And in 1992 the president of Adobe, Charles Geschke, was kidnapped at gunpoint and rescued by the FBI.
Do you still dream of being an executive in a large company?
Last week I’ve attended the AWSome Day Athens 2018 (huge thanks to Qobo for the opportunity). There aren’t that many technology events in Cyprus, so I’m constantly on the lookout for events in Europe.
AWSome Day Athens is part of the Amazon’s AWSome Day Global Series, which are one day events organized all throughout the world. The events are usually for a single day, featuring the speakers from both Amazon AWS team and some of their prominent clients from the area. AWSome Day Athens 2018 was done in partnership with Beat.
This website uses cookies to improve your experience while you navigate through the website. Out of these, the cookies that are categorized as necessary are stored on your browser as they are essential for the working of basic functionalities of the website. We also use third-party cookies that help us analyze and understand how you use this website. These cookies will be stored in your browser only with your consent. You also have the option to opt-out of these cookies. But opting out of some of these cookies may affect your browsing experience.
Necessary cookies are absolutely essential for the website to function properly. This category only includes cookies that ensures basic functionalities and security features of the website. These cookies do not store any personal information.
Any cookies that may not be particularly necessary for the website to function and is used specifically to collect user personal data via analytics, ads, other embedded contents are termed as non-necessary cookies. It is mandatory to procure user consent prior to running these cookies on your website.