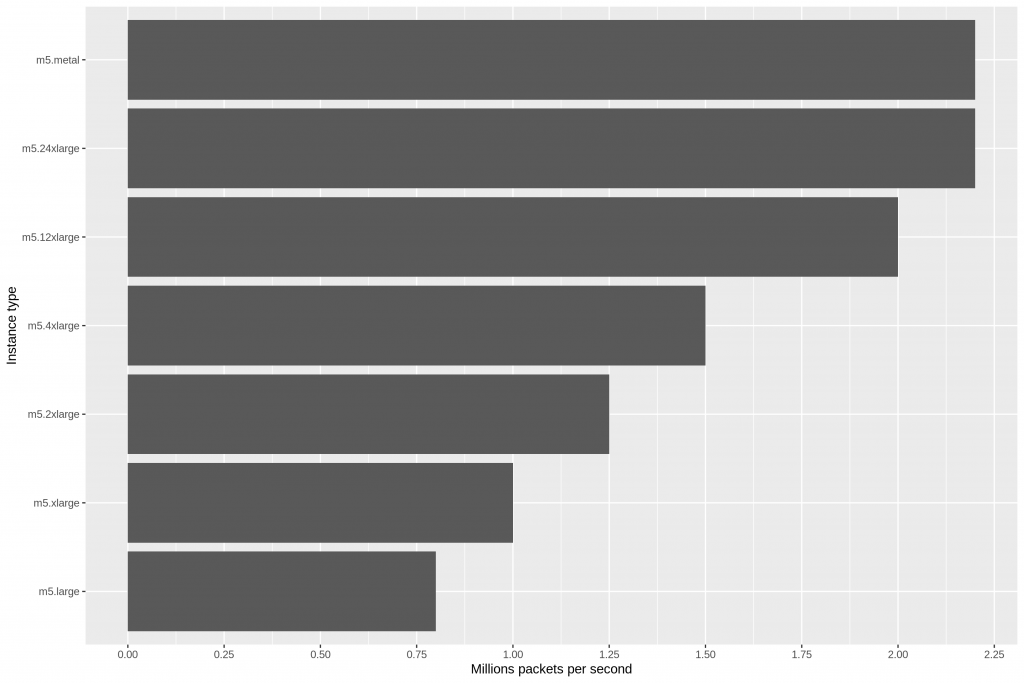
“Packets-per-second limits in EC2” is an interesting dive into network limits on the Amazon EC2. Even if you aren’t hitting any limits yet, this article provides plenty of useful information, including benchmarking tools and quick reference links for Enhanced Networking.
The conclusion of the article is:
By running these experiments, we determined that each EC2 instance type has a packet-per-second budget. Surprisingly, this budget goes toward the total of incoming and outgoing packets. Even more surprisingly, the same budget gets split between multiple network interfaces, with some additional performance penalty. This last result informs against using multiple network interfaces when tuning the system for higher networking performance.
The maximum budget for m5.metal and m5.24xlarge is 2.2M packets per second. Given that each HTTP transaction takes at least four packets, we can translate this to a maximum of 550k requests per second on the largest m5 instance with Enhanced Networking enabled.